

機械学習とAI(人工知能)、そしてディープラーニング(深層学習)。最近よく耳にするこれらの言葉、何がどう違うのかご存じですか?AI(人工知能)という言葉はすでに私たちの生活の中で一般的になりつつありますが、その中には「機械学習」や「ディープラーニング」といった専門用語が混在しています。
実は、これらの違いを理解することで、AIの仕組みや可能性がぐっと身近に感じられるようになるんです。
今回の記事では、AIの中でも特に重要な「機械学習」と、その中から生まれた「ディープラーニング」の基本をわかりやすく解説します。
どのようにして機械が人間のように学ぶのか、そしてそれが私たちの生活にどんな変化をもたらしているのか、興味が湧いてきませんか?
さあ、まずはAIと機械学習の関係からひも解いていきましょう。
- ChatGPTなどの生成AIが話題になっているので、改めてAIについての基礎知識をおさえておきたい方
- AIに興味があり具体的に機械学習や深層学習(ディープラーニング)について学習して行きたい方
- 機械学習って言葉をよく耳にするけど、実際に何かあまり良く分からない方
 るい
るい生成AIの普及が驚くスピードで広がっており、AIに関心を持つ人々が多くなったよね。今後は、AIに関する基礎知識が求められるようになってくるから改めて基礎から学んでみよう!
機械学習とは?AI(人工知能)との違いを徹底解説

AI(人工知能)の基本的な概念
AI(人工知能)は、人間の知能を模倣し、学習、問題解決、パターン認識(推論、判断、認識)などの人間と同じ知的な処理能力を持つコンピューターシステムを指します。
AIの基本的な概念について以下に説明します。
AIの定義
AIの明確な定義は研究者によって異なりますが、一般的には以下のように理解されています。
- 人間の知能をコンピューターで人工的に再現したもの
- 自然言語の理解、論理的推論、経験からの学習などを行うプログラム
- 人間が行う知的な作業を機械に代行させる技術
AIの主な特徴
- 自律性: 人間の指示がなくても作業を遂行できる能力
- 適応性: 学習や経験を通じて能力を向上させる能力
AIの種類
- 特化型AI (弱いAI): 特定のタスクに特化したAI
- 汎用AI (強いAI): 人間のように多様なタスクに対応できるAI (現時点では実現していない)
AIの学習方法
- 機械学習: データから学習し、パターンを見つけ出す手法
- 教師あり学習
- 教師なし学習
- 強化学習
- ディープラーニング (深層学習): 多層のニューラルネットワークを用いた機械学習の一種
AIの主要技術
- ニューラルネットワーク: 人間の脳の神経回路を模倣した情報処理モデル
- 自然言語処理(NLP): 人間の言語を理解・生成する技術
- コンピュータービジョン: 画像や動画を理解する技術
AIの応用分野
- 画像認識・音声認識
- 自動運転
- 医療診断支援
- 金融取引の予測
- 翻訳・要約
- パーソナルアシスタント
AIは日々進化を続けており、今後さらに多くの分野で活用されることが期待されています。
AIの歴史について
AIの歴史は1950年代から始まり、現在まで3つの主要なブームを経験しています。それぞれのブームの特徴と重要な出来事を詳しく見ていきましょう。
第1次AIブーム (1950年代後半〜1960年代)
このブームは「推論」と「探索」がキーワードでした。
- 1950年:アラン・チューリングが「チューリングテスト」を提唱。
- 1956年:ダートマス会議で「人工知能(AI)」という言葉が初めて使用される。
- 1964年:最初の対話型AI「ELIZA」が開発される。
この時期のAIは、迷路やチェスなどの単純なゲームを解くことはできましたが、現実世界の複雑な問題を解決することはできませんでした。
第2次AIブーム (1980年代)
このブームでは「知識表現」と「エキスパートシステム」が中心となりました。
- 1980年代:コンピューターに知識を与え、問題解決を行う「エキスパートシステム」の研究・開発が進む。
- 1984年:一般常識をデータベース化する「Cycプロジェクト」が開始。
- 1986年:ニューラルネットワークの学習アルゴリズム「誤差逆伝播法」が発表される。
しかし、必要な知識を全て人間が入力しなければならず、膨大な作業が必要でした。
第3次AIブーム (2000年代〜)
このブームでは、「機械学習」と「特徴表現学習」が中心となってきました。
- 2000年代:大量のデータからパターンを学習する「機械学習」が実用化
- 2006年:より複雑な判断が可能な「ディープラーニング(深層学習)」が実用化
- 2011年:IBMのAIシステム「Watson」がクイズ番組で人間のチャンピオンに勝利
- 2016年:GoogleのAI「AlphaGo」がプロの囲碁棋士に勝利
現在のAIは、画像認識、自然言語処理、音声認識など多様な分野で実用化が進んでいます。
現在
生成AIが誕生してから大きな注目を集め、世界中に一気に普及した点を考慮して現在は、AIブームの真っ只中と言っても過言ではないでしょう。
対話型AI(ChatGPT等)、動画生成AI(Runway)や画像生成AI(Midjourney等)などが登場し、大きな話題となっています。
AIの歴史は、技術の進歩と社会の期待が交錯しながら発展してきました。
現在のAIブームは、過去のブームよりも広範囲で実用化が進んでおり、今後さらに私たちの生活やビジネスに大きな影響を与えていくことが予想されます。
以下は、ChatGPT、動画生成AI、その他の生成AIについての記事ですので、是非参考にしてみてください。



機械学習の仕組みと役割

機械学習の仕組み
機械学習は、大量のデータを用いてコンピューターに学習させ、パターンや規則性を見出す技術です。その基本的な仕組みは以下の通りです。
- データ収集: 学習に必要な大量のデータを収集します。
- 特徴抽出: データから重要な特徴や属性を抽出します。
- アルゴリズムの選択: 問題に適した機械学習アルゴリズムを選びます。
- モデルの訓練: 選択したアルゴリズムを用いてデータからモデルを構築します。
- 評価と調整: モデルの性能を評価し、必要に応じて調整を行います。
- 予測・分類: 訓練されたモデルを用いて新しいデータに対する予測や分類を行います。
機械学習では、コンピューターが反復的に学習を行うことで、データの中に潜む特徴や規則性を見つけ出すことができます。
機械学習で用いる特徴量(注目すべきデータの特徴)を決めているのは人間でした。
この特徴量の選び方が良いか悪いかによって機械学習の性質を決定づけます。
機械学習の役割
機械学習は以下のような重要な役割を果たしています。
- パターン認識: 大量のデータから有意義なパターンを発見し、洞察を得ることができます5。
- 予測分析: 過去のデータを基に将来の傾向や結果を予測します。例えば、需要予測や売上予測などに活用されま。
- 自動化: 人間が行っていた判断や作業を自動化することで、効率化やコスト削減を実現します。
- 意思決定支援: データに基づいた客観的な意思決定をサポートします。
- 個別化・パーソナライゼーション: ユーザーの行動や嗜好を学習し、個々のニーズに合わせたサービスを提供します。
- 異常検知: 通常とは異なるパターンや動作を検出し、不正や故障の早期発見に役立ちます。
- 画像・音声認識: 画像や音声データを解析し、物体の識別や音声の文字起こしなどを行います。
これらの役割により、機械学習は様々な産業分野で活用され、ビジネスプロセスの改善や新しいサービスの創出に貢献しています。
例えば、金融業界での不正検知、製造業での品質管理、医療分野での診断支援など、幅広い応用が進んでいます。
機械学習は、人間の能力を補完・拡張し、データから価値を創出する重要な技術として、今後もさらなる発展が期待されています。
AIと機械学習の違いとは?
| 内容 | AI | 機械学習 |
|---|---|---|
| 定義と範囲 | 人間の知能を模倣するコンピューターシステム全般を指す広い概念 | AIの一分野で、データから学習して予測や決定を行う技術 |
| 目的 | 複雑な人間のタスクを機械に効率的に完了させること | 大量のデータを分析してパターンを特定し、結果を生成すること |
| 手法 | 機械学習以外にも様々な手法を含む | 教師あり学習と教師なし学習に分類される特定のアルゴリズムを使用 |
| 適用範囲 | 広範な問題解決や意思決定に適用可 | 特定のタスクに特化している |
| 学習能力 | すべてのAIが学習能力を持つわけではない | 本質的に学習と改善を行う |
つまり、機械学習はAIの一部であり、AIを実現するための重要な技術の1つですが、AIはより広範な概念で機械学習以外の技術も含んでいます。
ディープラーニングの基本と機械学習との関係
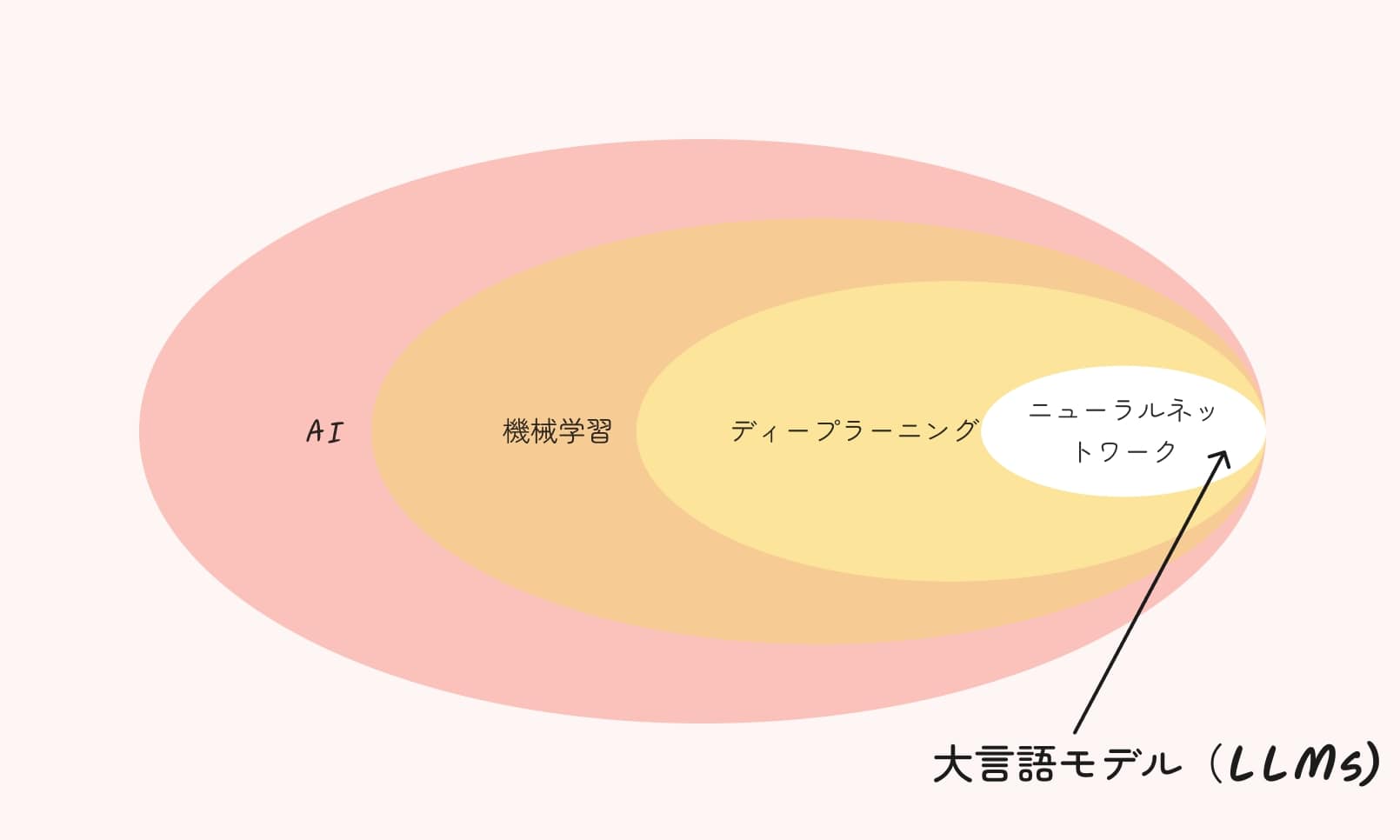
ディープラーニングとは?基礎から解説
ディープラーニングは、人工知能技術の一種で、人間の脳の仕組みを模倣した多層のニューラルネットワークを用いて、大量のデータから特徴や規則性を自動的に学習する手法です。
以下にディープラーニングの基本的な概念と特徴を説明します。
ディープラーニングの仕組み
ディープラーニングは、多層のニューラルネットワーク(深層ニューラルネットワーク)を使用します。
- 入力層:データを受け取る
- 隠れ層:複数の層で構成され、データの特徴を抽出・処理
- 出力層:最終的な結果を出力
各層は多数のニューロン(ノード)で構成され、ニューロン間の結合の強さ(重み)を調整することで学習を行います。
ディープラーニングの特徴
- 自動的な特徴抽出
-
人間が手動で特徴を設計する必要がなく、データから自動的に重要な特徴を学習します。
- 高い表現力
-
多層構造により、複雑なパターンや抽象的な概念を学習できます。
- エンドツーエンド学習
-
入力から出力まで一貫して学習できるため、中間処理を人間が設計する必要がありません。
- 大量のデータが必要
-
高い性能を発揮するには、大量の学習データが必要です。
- 計算コストが高い
-
多層構造のため、学習に時間と計算リソースがかかります。
ディープラーニングの応用分野
ディープラーニングは以下のような分野で広く応用されています。
- 画像認識:物体検出、顔認識など
- 自然言語処理:機械翻訳、感情分析など
- 音声認識:音声をテキストに変換など
- 自動運転:周囲の環境認識、経路計画など
- 医療:画像診断、新薬開発など
- 金融:株価予測、不正検知など
ディープラーニングの学習方法
大量の学習データを収集・前処理
ニューラルネットワークの構造を決定
データを用いてモデルのパラメータ(重み)を最適化
学習したモデルの性能を検証
ハイパーパラメータの調整や追加学習
ディープラーニングは、機械学習の一種でありAIの実現手法の1つです。従来の機械学習手法と比べて、より複雑なパターンを学習できる点が特徴で、近年のAI技術の発展に大きく貢献しています。
ニューラルネットワークの重要性
ニューラルネットワークは現代の人工知能技術の中核を成す重要な概念です。
その重要性について以下に詳しく解説します。
ニューラルネットワークの基本概念と歴史
ニューラルネットワークは、人間の脳の神経細胞(ニューロン)とその結合を模倣した情報処理モデルです。
多数のノード(ニューロン)が層状に連結され、各ノード間の結合の強さ(重み)を調整することで学習を行います。
ニューラルネットワークの歴史は、1958年に米国の心理学者フランク・ローゼンブラットによって提案された単純パーセブトロンというニューラルネットワークから始まります。
ニューラルネットワークは、1960年代にブームとなりましたが、 マービン・ミンスキーによって、特定の条件下の単純パーセプトロンは、直線で分離できるような単純な問題しか解けないということが指摘されました。(「パーセプトロンの性能と限界に関する論文」)
3層や多層にしても学習精度が上がらなかったのですが、多層にして、誤差逆伝播法(バックプロパゲーション)と呼ばれる方法を使って学習させて克服できることが示されました。
その後、入力したものと同じものを出力するように学習する自己符号化器(オートエンコーダ)の研究や、層の間でどのように情報を伝達するかを調整する活性化関数の工夫などにより、より多層にしていっても学習することができるようになりました。
このようにして、学習精度の高い多層のニューラルネットワークの構築が可能となり、データ料の増加とハードウェアの処理能力向上もあり、ディープラーニングがブームとなっていきます。
ニューラルネットワークの重要性
- 高い表現力
-
ニューラルネットワークは複雑な非線形関係を表現できるため、従来の手法では困難だった複雑なパターンの認識や予測が可能になりました。
- 自動的な特徴抽出
-
従来の機械学習手法では、人間が手動で特徴を設計する必要がありましたが、ニューラルネットワークは入力データから自動的に重要な特徴を抽出します。
- 汎用性
-
画像認識、自然言語処理、音声認識など、様々な分野で高い性能を発揮します。同じアーキテクチャを異なる問題に適用できる汎用性の高さが特徴です.
- スケーラビリティ
-
データ量やモデルの規模を大きくすることで、性能を向上させることができます。これにより、ビッグデータ時代に適した学習手法となっています。
- エンドツーエンド学習
-
入力から出力まで一貫して学習できるため、中間処理を人間が設計する必要がありません。これにより、より効率的かつ効果的な学習が可能になります。
- 転移学習の可能性
-
ある分野で学習したモデルを別の関連分野に転用することで、学習の効率化や少量データでの学習が可能になります。
- 並列処理との親和性
-
ニューラルネットワークの構造は並列処理に適しており、GPUなどの並列計算機を用いることで高速な学習と推論が可能です。
- 継続的な技術革新
-
深層学習の登場以降、新しいアーキテクチャや学習手法が次々と提案され、性能が急速に向上しています。これにより、AIの応用範囲が急速に拡大しています。
応用分野
ニューラルネットワークは以下のような幅広い分野で応用されています。
- コンピュータビジョン(画像認識、物体検出など)
- 自然言語処理(機械翻訳、感情分析など)
- 音声認識・合成
- 推薦システム
- 自動運転
- 医療診断支援
- 金融(株価予測、不正検知など)
- ゲームAI
ニューラルネットワークの重要性は、その高い表現力と汎用性、そして継続的な技術革新にあります。これらの特性により、ニューラルネットワークは現代のAI技術の中心的な役割を果たし、様々な分野で革新的なソリューションを生み出しています。
機械学習とディープラーニングの違い
| 特徴 | 機械学習 | ディープラーニング |
|---|---|---|
| 定義 | データから学習し判断や予測を行う手法 | 機械学習の一種で、多層ニューラルネットワークを用いた手法 |
| 特徴量抽出 | 人間が手動で設計する必要がある | 自動的に特徴を抽出する |
| データ量 | 比較的少量のデータでも機能する | 大量のデータを必要とする |
| 処理能力 | 低〜中程度の処理能力で実行可能 | 高い処理能力(GPU等)を必要とする |
| 解釈性 | 比較的解釈しやすい | 解釈が困難な「ブラックボックス」的な面がある |
| 適用分野 | 構造化データの分析に適している | 画像、音声、自然言語等の非構造化データに強い |
| 学習時間 | 比較的短い | 長時間の学習が必要 |
| 精度 | データと手法に依存するが、一般的に中程度 | 大量のデータと適切な設計で非常に高精度 |
| 人間の介入 | モデル設計や特徴選択に人間の専門知識が必要 | 最小限の人間の介入で学習可能 |
この表は、機械学習とディープラーニングの主要な違いを簡潔にまとめたものです。
ただし、両者の境界は必ずしも明確ではなく、多くの場合はタスクや利用可能なデータ、リソースに応じて適切な手法を選択することが重要です。
 ミラ
ミラ解釈が困難でブラックボックス化してしまうような危険性がある場合は、まさに自然言語処理が得意な生成AIに分かりやすく説明してもらうことがいいかも💡
機械学習の種類と手法の紹介
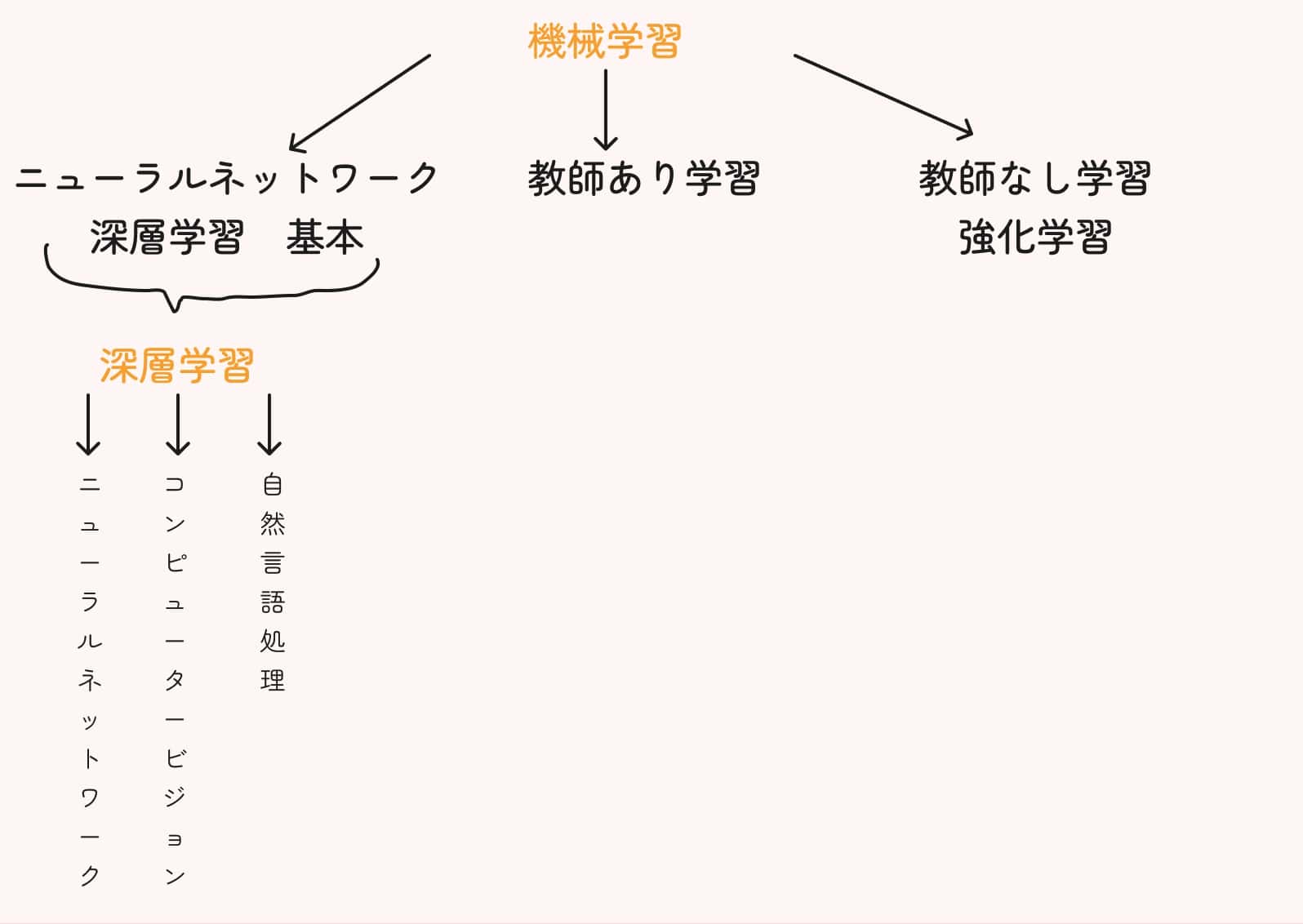
教師あり学習・教師なし学習・強化学習とは?
機械学習の主要な3つのアプローチである教師あり学習、教師なし学習、強化学習について、それぞれの特徴と違いを分かりやすく説明します。
特徴:
- 入力データと正解(出力)のペアを使用
- モデルは入力から正解を予測するよう学習
- 予測と実際の正解の差(誤差)を最小化するよう調整
例:
- 画像分類:犬や猫の画像にそれぞれのラベルを付けて学習
- スパムメール検出:スパムか否かのラベル付きメールデータで学習
用途:
- 分類問題
- 回帰問題
特徴:
- 正解ラベルを必要としない
- データの内在する構造やグループを発見
- パターンや類似性に基づいてデータを整理
例:
- 顧客セグメンテーション:購買行動に基づく顧客グループの分類
- 異常検知:通常とは異なるパターンの特定
用途:
- クラスタリング
- 次元削減
- パターン認識
特徴:
- エージェントが環境の中で行動を選択
- 行動の結果に基づいて報酬を受け取る
- 長期的な報酬を最大化するよう学習
例:
- ゲームAI:チェスや囲碁などのゲームで最適な手を学習
- ロボット制御:ロボットの動作を環境に応じて最適化
用途:
- 自動運転
- ゲームAI
- リソース管理
| 特徴 | 教師あり学習 | 教師なし学習 | 強化学習 |
|---|---|---|---|
| データ | ラベル付きデータ | ラベルなしデータ | 環境との相互作用 |
| 目的 | 予測・分類 | パターン発見 | 最適な行動方針の学習 |
| フィードバック | 即時(誤差) | なし | 遅延(報酬) |
| 適用例 | スパム検出、画像分類 | 顧客セグメンテーション | ゲームAI、ロボット制御 |
これらの学習方法は、それぞれ異なる問題や状況に適しています。実際の応用では、これらを組み合わせたり、タスクに応じて最適な方法を選択したりすることが重要です。
代表的なアルゴリズムとその特徴
教師あり学習、教師なし学習、強化学習の各手法における代表的なアルゴリズムとその特徴を以下の表にまとめてみました。
| 学習手法 | 代表的アルゴリズム | 特徴 |
|---|---|---|
| 教師あり学習 | 1. 回帰分析 | • 連続的な値を予測 • 入力と出力の関係を線形モデルで表現 |
| 2. サポートベクターマシン(SVM) | • 分類問題に強い • 高次元空間での分離平面を見つける | |
| 3. 決定木・ランダムフォレスト | • 解釈しやすい • 複数の決定木を組み合わせて精度向上 | |
| 4. ロジスティック回帰 | • 二値分類に適している • 確率を出力する | |
| 教師なし学習 | 1. k-means法 | • データをk個のクラスタに分類 • シンプルで実装が容易 |
| 2. 主成分分析(PCA) | • 次元削減に使用 • データの重要な特徴を抽出 | |
| 3. 自己組織化マップ(SOM) | • 高次元データの可視化 • ニューラルネットワークの一種 | |
| 強化学習 | 1. Q学習 | • 行動価値関数を学習 • オフポリシー型の手法 |
| 2. SARSA | • 実際に行動した結果を用いて学習 • オンポリシー型の手法 | |
| 3. モンテカルロ法 | • エピソード全体の報酬を使用 • 完全なエピソードが必要 |
各代表的なアルゴリズムについては、今後のシリーズの記事でさらに深掘りしていきますので、ここで具体的な説明は割愛します。
各学習手法の特徴:
- 教師あり学習:
- ラベル付きデータを使用
- 予測や分類タスクに適している
- モデルの解釈がしやすい
- 教師なし学習:
- ラベルなしデータを使用
- データの潜在的な構造やパターンを発見
- クラスタリングや次元削減に適している
- 強化学習:
- 環境との相互作用を通じて学習
- 長期的な報酬を最大化することが目的
- 複雑な意思決定問題に適している
これらの手法は、問題の性質や利用可能なデータの種類に応じて選択されます。
実際の応用では、これらの手法を組み合わせたり、深層学習と統合したりすることも多くあります。
各手法のメリットとデメリット
教師あり学習のメリットとデメリット
| メリット | デメリット |
|---|---|
| 高い予測精度 – ラベル付きデータによる正確な予測・分類が可能 | 大量のラベル付きデータが必要 – データ収集と正確なラベル付けに時間とコストがかかる |
| 応用のしやすさ – 明確な目的に対して結果を出しやすい | 過学習のリスク – トレーニングデータに過度に適合し、新しいデータに対応ができなく可能性 |
| アルゴリズムの豊富さ – 目的やデータに応じて最適なアルゴリズムを選択可能 | ラベルの品質依存 – 誤ったラベル付けが性能低下につながる |
| 結果の解釈のしやすさ – 予測や分類の根拠が比較的理解しやすい | 柔軟性の欠如 – 新しいデータや未来の状況への対応が難しい |
| 汎用性の限界 – 特定のタスクに特化しており、他のタスクへの転用が困難 |
教師あり学習の主な利点は、正解データを用いることで高い予測精度が得られ、明確な目的に対して効果的に結果を出せることです。
また、結果の解釈がしやすく、様々なアルゴリズムから選択できる点も強みです。
一方で欠点としては、大量のラベル付きデータが必要で、その収集とラベル付けに時間とコストがかかる点が挙げられます。
また、過学習のリスクがあり、ラベルの品質に依存するため、誤ったラベル付けが精度低下につながる可能性があります。
さらに、新しいデータや状況への対応が難しく、特定のタスクに特化するため汎用性に欠ける面もあります。これらの利点と欠点を理解し、適切な状況で教師あり学習を活用することが重要です。
教師なし学習のメリットとデメリット
| メリット | 欠点 |
|---|---|
| ラベル付けが不要で低コスト | 結果の解釈が難しい |
| 隠れたパターンや構造を発見可能 | 結果の評価が困難 |
| データの初期探索に適している | パラメータ選択が難しい |
| 事前知識が少なくても適用可能 | ノイズに敏感 |
| 大規模データにスケーラブル | 正確性が教師あり学習より劣る |
| 新しい知見を得られる可能性 | 特定のタスクに特化できない |
| 柔軟性が高い | 結果が不安定になる可能性 |
教師なし学習の主な利点は、ラベル付けデータが不要なため低コストで実施でき、データの隠れたパターンや構造を発見できる点です。
また、事前知識が少なくても適用可能で、大規模データにも対応できる柔軟性があります。一方で欠点としては、結果の解釈や評価が難しく、パラメータ選択に試行錯誤を要する点が挙げられます。
また、ノイズに敏感で結果が不安定になる可能性があり、教師あり学習と比べて特定タスクでの正確性は劣る傾向にあります。
教師なし学習は、データ探索や新しい知見の発見には適していますが、結果の信頼性や解釈には注意が必要です。用途や目的に応じて、教師あり学習と適切に使い分けることが重要です。
強化学習のメリットとデメリット
| メリット | デメリット |
|---|---|
| 複雑な環境での意思決定に適している | 学習に時間がかかる |
| 連続的な行動や長期的な戦略を学習できる | 大量の試行錯誤が必要 |
| 事前知識が少なくても適用可能 | 適切な報酬設計が難しい |
| 環境の変化に適応できる | 局所最適解に陥りやすい |
| 人間の介入なしで自律的に学習可能 | 安定性と収束性の問題がある |
| 新しい創造的な解決策を見つけられる | 実世界での適用に制約がある |
| マルチエージェントシステムに適用可能 | 解釈性が低い |
強化学習の主な利点は、複雑な環境での意思決定や長期的な戦略の学習に適していることです。
環境の変化に適応でき、人間の介入なしで自律的に学習できる点も大きな強みです。
また、事前知識が少なくても適用可能で、新しい創造的な解決策を見つけられる可能性があります。
一方で欠点としては、学習に時間がかかり、大量の試行錯誤が必要な点が挙げられます。
適切な報酬設計が難しく、局所最適解に陥りやすいという課題もあります。
局所最適解に陥いるとは、例えば、報酬関数が適切に設計されていない場合、エージェントが短期的な報酬を最大化する行動を学習し、長期的には最適でない戦略に陥る可能性があったり、環境が複雑で状態空間が大きい場合、エージェントが探索できる範囲が限られ、局所的に良い解を見つけても、それが大域的な最適解でない可能性が高くなるような場合が挙げられます。
また、安定性と収束性の問題があり、実世界での適用には制約があることも欠点です。
さらに、学習プロセスの解釈性が低いため、結果の説明が難しい場合があります。
強化学習は、動的で複雑な環境での意思決定問題に特に適していますが、適用には慎重な設計と十分な計算リソースが必要です。これらの利点と欠点を考慮し、適切な状況で強化学習を活用することが重要です。
マルチエージェントシステム(MAS)とは、複数の「エージェント」が存在し、相互に作用しながら全体として機能するシステムのことです。
| 特徴 | 説明 |
|---|---|
| 複数のエージェントの存在 | • 各エージェントは自律的に考え、行動する主体 • エージェントはAI、ロボット、ソフトウェアなど様々な形態 |
| エージェント間の相互作用 | • エージェント同士がコミュニケーションを取る • 協調または競合関係が生まれる |
| 分散型の問題解決 | • 複雑な問題を複数のエージェントで分担して解決 • 柔軟な問題解決が可能 |
| 創発的な振る舞い | • 個々の単純な行動から複雑な全体挙動が生まれる |
| 適応性と学習 | • エージェントは環境や他のエージェントから学習し適応 |
| 応用分野 | • 交通管制、自動運転、物流最適化、ロボティクス、経済シミュレーションなど |
MASの具体例としては、複数のドローンが協調して空中に図形を描くドローンショーや、自動運転車と信号機が連携して交通流を最適化するシステムなどが挙げられます。
MASは複雑な実世界の問題を模倣し解決するのに適しており、今後さらに多くの分野での応用が期待されています。
ビジネス活用事例
画像認識における活用方法
製造業での品質管理
キューピー株式会社:惣菜の原料検査工程にディープラーニングを活用した画像認識を導入し、検査の自動化・効率化を実現しました。
小売業での無人店舗・商品識別
パナソニック: AI画像認識カメラを用いて顧客の行動を分析し、売上と顧客満足度の向上を図るシステム「Vieureka」を開発しました。棚にあるどの商品を手に取ったかまで検知可能となりました。
物流業での効率化
ユニクロ(ファーストリテイリング): 倉庫業務に画像認識AIを導入し、商品の入出庫、ピッキング作業、配送仕分けなどを自動化・最適化しました。
アパレル業界でのトレンド予測
ニューラルグループ株式会社: AI画像認識を使ってインターネット上のファッション関連画像を分析し、将来の流行を予測するシステムを開発しました。
これらの事例は、画像認識技術を活用することで業務の効率化、コスト削減、精度向上、新サービスの創出などを実現しています。
各業界の特性に合わせて画像認識技術を適用することで、さまざまなビジネス課題の解決につながっています。
ディープラーニングの導入とその可能性

クラウドを活用した導入方法
| 段階 | 内容 | 詳細 |
|---|---|---|
| 1. クラウドサービスの選択 | • 主要プロバイダーの比較 • ニーズに合ったサービスの選定 | • AWS、Google Cloud、Microsoft Azureなどを検討 • 機能、コスト、使いやすさを比較 |
| 2. データの準備と保存 | • クラウドストレージの利用 • データの前処理 | • 大量データを効率的に管理 • クラウド上でデータ加工も可能 |
| 3. モデルの開発と学習 | • クラウド環境でのモデル開発 • GPUインスタンスの活用 | • Jupyter Notebookなどの環境を利用 • 高速な学習が可能 |
| 4. モデルのデプロイと運用 | • 自動スケーリングの設定 • APIを通じたサービス提供 | • 需要に応じてリソースを調整 • モデルを外部から利用可能に |
| 5. モニタリングと改善 | • パフォーマンスの継続的監視 • モデルの再学習と改善 | • クラウドの監視ツールを使用 • 必要に応じてモデルを更新 |
クラウドを活用することで、ディープラーニングの導入障壁を大幅に下げることができ、企業は自社の課題解決や新しいサービス創出に集中できるようになります。
特に、大規模なデータ処理や複雑なモデルの学習が必要な場合、クラウドの活用は非常に効果的です。
ディープラーニングの威力
ディープラーニングの威力は、上記の活用事例で挙げた通り、様々な業界での革新的な応用事例から見て取れます。
- 作業の自動化・効率化による大幅な人員削減とコスト削減
- 人間の目を超える高精度な検査・認識能力
- 24時間365日稼働可能な監視・点検システムの実現
- 危険作業や単調作業からの人間の解放
- 大量のデータ処理による迅速な意思決定支援
- 新たな価値創造や問題解決手法の提供
ディープラーニングは、従来の人間の能力や従来型のコンピューターシステムでは困難だった課題を解決し、業務プロセスを根本から変革する力を持っています。
これにより、生産性の向上、安全性の確保、新たなサービスの創出など、幅広い分野で革新的な変化をもたらしています。
導入における課題と対策
| 課題 | 詳細 | 対策 |
|---|---|---|
| 1. 大量のデータが必要 | • 学習に大量のデータが必要 • データ収集・整備に時間とコストがかかる | • データ拡張技術の活用 • クラウドソーシングでのデータ収集 • 転移学習の活用 |
| 2. 結果の解釈が困難 (ブラックボックス問題) | • モデルの判断根拠が不明確 • 説明責任を果たすのが難しい | • 説明可能AI(XAI)技術の導入 • シンプルなモデルとの組み合わせ • 結果の検証プロセスの確立 |
| 3. 高いコストとリソース | • 計算リソースの確保が必要 • 専門人材の確保にコストがかかる | • クラウドサービスの活用 • 外部のAI専門企業との連携 • 段階的な導入で初期投資を抑制 |
| 4. AI人材の不足 | • AI技術に精通した人材の確保が困難 | • 社内人材の育成プログラムの実施 • 外部のAI専門家との協業 • AIツールの活用 |
| 5. 倫理的・法的問題 | • AIの判断が倫理的問題を引き起こす可能性 • 法的責任の所在が不明確 | • AI倫理ガイドラインの策定と遵守 • 法的リスクの事前評価と対策 • 人間による監視・介入システムの構築 |
| 6. モデルの精度と安定性 | • 環境変化によるモデルの性能低下 • 予期せぬ誤作動の可能性 | • 定期的なモデルの再学習と更新 • ロバスト性を考慮したモデル設計 • アンサンブル学習の採用 |
これらの課題に適切に対処することで、ディープラーニングの導入をより効果的に進めることができます。
導入の目的や組織の状況に応じて、適切な対策を選択・実施することが重要です。
ビッグデータ時代における機械学習の役割

ビッグデータ解析のための機械学習
ビックデータ時代における機械学習の役割は、以下のようなものが挙げられます。
| 役割 | 説明 | 活用例 |
|---|---|---|
| パターン認識と予測 | 隠れた傾向を発見し、将来を予測 | 需要予測、株価分析 |
| 自動化と効率化 | データ処理・分析プロセスの自動化 | 製造業の品質管理 |
| 個別化 | 個々のニーズに合わせたサービス提供 | レコメンデーションシステム |
| 異常検知 | 通常と異なるパターンを検出 | 不正取引の検知 |
| 意思決定支援 | データに基づく客観的判断をサポート | 経営戦略立案 |
| 新知見の発見 | 複雑な関係性やインサイトを発見 | 新薬開発、疾病リスク予測 |
| リアルタイム処理 | ストリーミングデータの即時分析 | IoTデータ分析、交通情報分析 |
| 非構造化データ分析 | テキスト、画像、音声等の解析 | 画像認識、自然言語処理 |
これらの役割を通じて、機械学習はビッグデータから価値を引き出し、ビジネスや社会に大きな影響を与えています。例えば、製造業での予防保全、小売業での需要予測、金融業でのリスク分析など、様々な分野で活用されており、データドリブンな意思決定や新しいサービスの創出を可能にしています。
ただし、機械学習の活用には適切なデータの準備や、モデルの解釈性の確保、プライバシーへの配慮など、いくつかの課題もあります。
これらの課題に適切に対処しながら、ビッグデータと機械学習を組み合わせることで、より効果的なデータ活用が可能になります。
大量データを活用する方法とその効果
| 方法 | 具体的な手法 | 効果 |
|---|---|---|
| 1. データの収集と前処理 | • IoTデバイスからのリアルタイムデータ収集 • クラウドストレージの活用 • データクレンジングと正規化 | • 多様で大量のデータの活用 • 高品質なデータセットの構築 |
| 2. 分散処理と並列計算 | • Hadoopなどの分散処理フレームワーク活用 • GPUを用いた並列計算 | • 大規模データの高速処理 • 複雑なモデルの学習時間短縮 |
| 3. ディープラーニングの活用 | • 多層ニューラルネットワークによる特徴抽出 • 転移学習による既存モデルの再利用 | • 非構造化データの高精度分析 • 少データでの高性能モデル構築 |
| 4. リアルタイム学習と予測 | • ストリーミングデータを用いたオンライン学習 • エッジコンピューティングの活用 | • 最新データの即時モデル反映 • リアルタイムでの予測と意思決定 |
| 5. アンサンブル学習 | • 複数の機械学習モデルの組み合わせ • 異なるアルゴリズムや特徴量の統合 | • 予測精度の向上 • モデルの頑健性向上 |
- 高精度な予測と分析の実現
- 新たなパターンや知見の発見
- 業務プロセスの自動化と効率化
- パーソナライゼーションの向上
- リアルタイムでの意思決定支援
ビッグデータと機械学習を組み合わせることで、企業は競争力を高め、イノベーションを促進し、より効果的な意思決定を行うことが可能となります。
機械学習の歴史とこれからの方向性
機械学習の登場と発展の過程
記事の導入部分でご紹介したAIブームに沿って、発展過程をまとめてみましょう。
| 時期 | 主なできごと | 特徴 |
|---|---|---|
| 1940年代〜1950年代 (機械学習の起源) | • 1943年:ニューラルネットワークの概念提唱 • 1950年:チューリングテスト考案 • 1956年:「人工知能(AI)」という用語誕生 | • AIの基本概念の形成 • 理論的基盤の確立 |
| 1950年代後半〜1960年代 (第1次AIブーム) | • 1966年:対話型自然言語処理プログラム「ELIZA」開発 | • 「推論」と「探索」が中心テーマ • 単純な問題は解決可能に |
| 1980年代 (第2次AIブーム) | • 1984年:「Cycプロジェクト」開始 • 1986年:誤差逆伝播法の発表 | • 「知識」をテーマにした研究 • エキスパートシステムの発展 |
| 2000年代〜現在 (第3次AIブーム) | • 2012年:ディープラーニングによる画像認識の飛躍的進歩 • 2015年:AlphaGoがプロ囲碁棋士に勝利 | • 機械学習の実用化 • ビッグデータの活用 • ディープラーニングの台頭 |
械学習は、この第3次AIブームの中核技術として急速に発展しています。大量のデータと計算リソースの利用可能性が高まったことで、特にディープラーニングの分野で大きな進展が見られています。
これらの発展により、機械学習は画像認識、自然言語処理(NLP)、音声認識など様々な分野で実用化が進み、現在のAIブームを牽引しています。
DX推進における機械学習の役割
| 役割 | 内容 | 具体例 |
|---|---|---|
| 1. データ駆動型意思決定の促進 | • パターンや洞察の抽出 • 正確で迅速な意思決定支援 | • 予測分析 • リスク評価 |
| 2. 業務プロセスの自動化と効率化 | • 反復的タスクの自動化 • 複雑な判断の支援 | • 顧客対応の自動化 • 需要予測に基づく在庫管理 |
| 3. パーソナライゼーションの高度化 | • 個々のニーズに合わせたサービス提供 • 精緻なターゲティング | • レコメンデーションシステム • カスタマイズ広告 |
| 4. 新規ビジネスモデルの創出 | • データ分析からの新サービス開発 • 既存ビジネスの拡張 | • 予測保守サービス • AIを活用した金融商品 |
| 5. リアルタイム対応の実現 | • ストリーミングデータの分析 • 即時の状況把握と対応 | • 製造ラインでの品質管理 • 金融取引での不正検知 |
| 6. 継続的な学習と改善 | • 新データからの常時学習 • 変化する環境への適応 | • 顧客行動の変化への対応 • 市場トレンドの追跡 |
| 7. クロスファンクショナルな価値創造 | • 異部門データの統合・分析 • 新たな価値の創出 | • 最適な生産計画の立案 • 部門横断的な顧客理解 |
| 8. エッジコンピューティングとの融合 | • エッジでの機械学習処理 • リアルタイムで効率的なデータ処理 | • IoTデバイスでの即時分析 • 自動運転車の判断処理 |
これらの役割を通じて、機械学習はDXの核心である「デジタル技術による事業変革」を強力に推進する役割を果たすでしょう。
ただし、機械学習の効果的な活用には、質の高いデータの確保、適切なAI人材の育成・確保、倫理的な配慮などが不可欠です。
これらの課題に適切に対処しながら、機械学習を戦略的に活用することが、成功するDX推進の鍵となるでしょう。
未来を見据えた機械学習の展望
| 展望 | 内容 | 予想される影響 |
|---|---|---|
| 1. マルチモーダルAIの進化 | • 複数の入力タイプ(テキスト、画像、音声等)を処理 | • より自然なAIインターフェースの実現 • モデル性能の向上 |
| 2. エージェント型AIの台頭 | • タスク実行能力を持つAIの普及 | • 日常生活やビジネスでの実用的なAI活用の増加 |
| 3. オープンソースAIの発展 | • 高性能なオープンソースAIモデルの登場 | • AIの民主化 • 小規模組織でのAI活用促進 |
| 4. プライバシーとセキュリティの重視 | • プライベートモデルや特定ドメイン向けモデルの開発 | • データのプライバシーとセキュリティの向上 |
| 5. AI人材の需要増加 | • MLOps等の専門家需要の高まり | • AI関連の雇用市場の拡大 • 教育・トレーニングの重要性増加 |
| 6. 産業への深い統合 | • 様々な産業でのAI活用の進展 | • 業務プロセスの根本的な変革 • 新しいビジネスモデルの創出 |
| 7. エッジAIの普及 | • データソースでの処理の重要性増加 | • リアルタイムの洞察獲得 • データプライバシーの向上 |
| 8. 倫理的考慮の重要性 | • AIの公平性、透明性、説明可能性への注目 | • 倫理的AI開発の促進 • 関連規制の整備 |
これらのトレンドは、AIと機械学習が私たちの生活やビジネスにより深く統合されていく方向性を示しています。
同時に、技術の進歩に伴う倫理的・社会的課題にも注目が集まるでしょう。
最後に
この記事では、機械学習とAIをテーマに、AI(人工知能)と機械学習の関係から、機械学習とさらに深層学習(ディープラーニング)、強化学習などと比較しながら各手法のメリット・デメリット、ビジネスでの活用例を含めながら、機械学習の役割、今後の展望について解説してきました。
機械学習は単なる技術ではなく、ビジネスや社会を変革する力を持っています。そのため、技術者だけでなく、ビジネスパーソンや学生にとっても、機械学習の基本を理解することは今後ますます重要になると考えられます。
機械学習について学ぼうシリーズ①となり、今後シリーズでさらに細かい点について解説していく予定です。
 massa
massa当ブログでは、初心者からでもAIを学べるようAIについての知識の集約、解説、ChatGPTのおすすめスキルなどを発信して行きます。
よかったら、是非、ブックマーク&フォローしてください。
-

機械学習について学ぼうシリーズ②初心者向け!機械学習で必須のデータ準備と前処理テクニック〜機械学習アルゴリズム第1章
-
OpenAIが導入した「ChatGPT Canvas」最新機能を紹介! 基本的な使い方から活用方法まで詳細に解説
-
機械学習について学ぼうシリーズ①機械学習とAIとの違いって?ディープラーニングは何が違う?
-
ChatGPT 高度な音声モードついに一般向けリリース!ChatGPTで実現するリアルタイム会話の可能性 次の時代は音声モードへ!?
-
ChatGPTの最新情報!最新モデルOpenAI-o1とは?使い方やGPT-4oとの比較、その活用方法、応用分野や今後の展望について
-
Open AI 次世代モデル『GPT NEXT』、プロジェクトStrawberryとは?|AIの驚異的な進化スピードによる今後の展望






