

機械学習において、優れたモデルを構築するために最も重要なステップの一つが「データ準備」と「前処理」です。
データの質が低ければ、どんなに高度なアルゴリズムを使用しても、望む結果を得ることはできません。
では、データ準備と前処理とは具体的に何をする作業なのでしょうか?そして、これらのステップがなぜ機械学習において必須なのか?
機械学習について学ぼうシリーズ②、初心者の方に向けた本記事では、データの収集から前処理、さらに機械学習のアルゴリズムまで、機械学習モデルの精度を劇的に向上させるため、データの前処理から機械学習のアルゴリズムをわかりやすく解説します。
初めて機械学習を学ぶ方でも理解しやすいよう、ステップごとに具体例を交えて説明しますので、ぜひ最後までご覧ください。
- ChatGPTなどの生成AIが話題になっているので、改めてAIについての基礎知識をおさえておきたい方
- AIに興味があり具体的に機械学習について学習して行きたい方
- 機械学習って言葉をよく耳にするけど、実際に何かあまり良く分からない方
 ミラ
ミラ機械学習をしたいとしても、まずはデータを集めてこないとだよね。集めてきたデータをそのまま学習させると正確な結果が得られなくなってしまうから、その前処理がとっても大事なんだよね。具体的にどうしたら良いのか一緒に見ていきましょう!
機械学習のついての復習
機械学習の仕組み
機械学習は、大量のデータを用いてコンピューターに学習させ、パターンや規則性を見出す技術です。その基本的な仕組みは以下の通りです。
- データ収集: 学習に必要な大量のデータを収集します。
- 特徴抽出: データから重要な特徴や属性を抽出します。
- アルゴリズムの選択: 問題に適した機械学習アルゴリズムを選びます。
- モデルの訓練: 選択したアルゴリズムを用いてデータからモデルを構築します。
- 評価と調整: モデルの性能を評価し、必要に応じて調整を行います。
- 予測・分類: 訓練されたモデルを用いて新しいデータに対する予測や分類を行います。
機械学習では、コンピューターが反復的に学習を行うことで、データの中に潜む特徴や規則性を見つけ出すことができます。
機械学習で用いる特徴量(注目すべきデータの特徴)を決めているのは人間でした。
この特徴量の選び方が良いか悪いかによって機械学習の性質を決定づけます。
機械学習の役割
機械学習は以下のような重要な役割を果たしています。
- パターン認識: 大量のデータから有意義なパターンを発見し、洞察を得ることができます5。
- 予測分析: 過去のデータを基に将来の傾向や結果を予測します。例えば、需要予測や売上予測などに活用されま。
- 自動化: 人間が行っていた判断や作業を自動化することで、効率化やコスト削減を実現します。
- 意思決定支援: データに基づいた客観的な意思決定をサポートします。
- 個別化・パーソナライゼーション: ユーザーの行動や嗜好を学習し、個々のニーズに合わせたサービスを提供します。
- 異常検知: 通常とは異なるパターンや動作を検出し、不正や故障の早期発見に役立ちます。
- 画像・音声認識: 画像や音声データを解析し、物体の識別や音声の文字起こしなどを行います。
これらの役割により、機械学習は様々な産業分野で活用され、ビジネスプロセスの改善や新しいサービスの創出に貢献しています。
例えば、金融業界での不正検知、製造業での品質管理、医療分野での診断支援など、幅広い応用が進んでいます。
機械学習は、人間の能力を補完・拡張し、データから価値を創出する重要な技術として、今後もさらなる発展が期待されています。
機械学習や深層学習などの概要について以下の記事で解説しているので、是非参考にしてみてください。

初心者向けの機械学習データ準備の基本

データ収集と前処理の重要性
械学習における初心者向けのデータ準備において、データ収集と前処理は非常に重要な工程です。以下に、その重要性について解説します。
データ収集の重要性
機械学習の成功は、質の高いデータに大きく依存します。適切なデータを収集することは、モデルの精度と信頼性を確保するための基礎となります。
- データの量と質: 機械学習には膨大なデータが必要ですが、単に量が多ければよいというわけではありません。データの質も同様に重要です。
- 代表性: 収集するデータは、解決しようとする問題や予測したい事象を適切に代表するものである必要があります。
- 多様性: 様々なシナリオや条件を網羅したデータを集めることで、モデルの汎用性が向上します。
前処理の重要性
収集したデータをそのまま機械学習アルゴリズムに投入することはほとんどありません。データの前処理は、モデルの性能を大きく左右する重要な工程です。
- データクリーニング: 欠損値、外れ値、ノイズなどを適切に処理することで、モデルの学習精度が向上します。
- 特徴量エンジニアリング: データから有用な特徴を抽出または生成することで、モデルの性能を大幅に改善できます。
- データ標準化: 異なるスケールの特徴量を統一することで、多くの機械学習アルゴリズムの性能が向上します2。
- 次元削減: 不要な特徴量を削除したり、主成分分析(PCA)などの手法を用いて特徴量の数を減らすことで、モデルの学習効率が上がります。
- モデルの精度向上
- 過学習のリスク低減
- 学習時間の短縮
- モデルの解釈可能性の向上
初心者にとって、データ収集と前処理は時間がかかり、ときに退屈な作業に感じられるかもしれません。しかし、この工程に十分な時間と労力を費やすことが、最終的に高性能で信頼性の高い機械学習モデルを構築するための鍵となります。
Pythonを使った基本的なデータ操作
Pythonを使った基本的なデータ操作について、Pandasを中心に解説します。
ワンポイント解説💡:Pandas(パンダス)とは、Pythonでデータの操作や分析を行うためのライブラリの一つです。特に、データの処理や集計、変換が簡単にできるため、機械学習やデータサイエンス分野で広く使われています。Pandasは、大量のデータを扱う際に効率的で使いやすいツールとして、多くのデータ科学者やエンジニアに重宝されています。
ワンポイント解説💡:Pythonのライブラリとは、特定の機能やツールを集めた再利用可能なコードの集まりです。Pythonライブラリを使うことで、プログラマが一からコードを書く手間を省き、簡単に高度な処理を行うことができます。ライブラリには、数値計算やデータ処理、機械学習、Web開発などさまざまな目的に対応するものがあり、Pythonが幅広い分野で利用される要因の一つです。
データの前処理
欠損値の処理
データセットには欠損値が含まれていることがよくあります。これらを適切に処理することが重要です。
ワンポイント解説💡:データの欠損値とは、データセット内で本来あるべき情報が抜けている状態を指します。たとえば、アンケート調査を行った際に、年齢や性別の項目に回答がなかった場合、その部分は欠損値と見なされます。機械学習では、このような欠損値があると、モデルの精度が下がったり、正確な予測ができなくなったりするため、必ず対処が必要です。欠損値が発生する理由はさまざまで、データ入力時のエラー、回答者が質問に答えなかった場合、あるいはセンサーやシステムの不具合などが原因となることがあります。欠損値を処理する方法としては、いくつかのアプローチがあります:
欠損値を処理する方法としては、いくつかのアプローチがあります。
- 欠損データの削除:欠損しているデータを含む行や列を削除する方法。簡単ですが、データ量が少なくなる可能性があり、特に大きなデータセットでは有効です。
- 平均値や中央値で埋める:数値データの場合、欠損部分に他のデータの平均値や中央値を代入する方法。データが偏らない場合に適しています。
- 前後のデータで埋める:時系列データの場合、前の値や後の値を使って欠損部分を補う方法です。

重複データの処理
データセットに重複がある場合、分析結果に影響を与える可能性があります。

 リサ
リサ実際保存されているデータって必ずしも完璧な状態で保存されているとは限らなくて、どこか抜けているデータがあったり、重複して保存されているデータがあたりするよね。
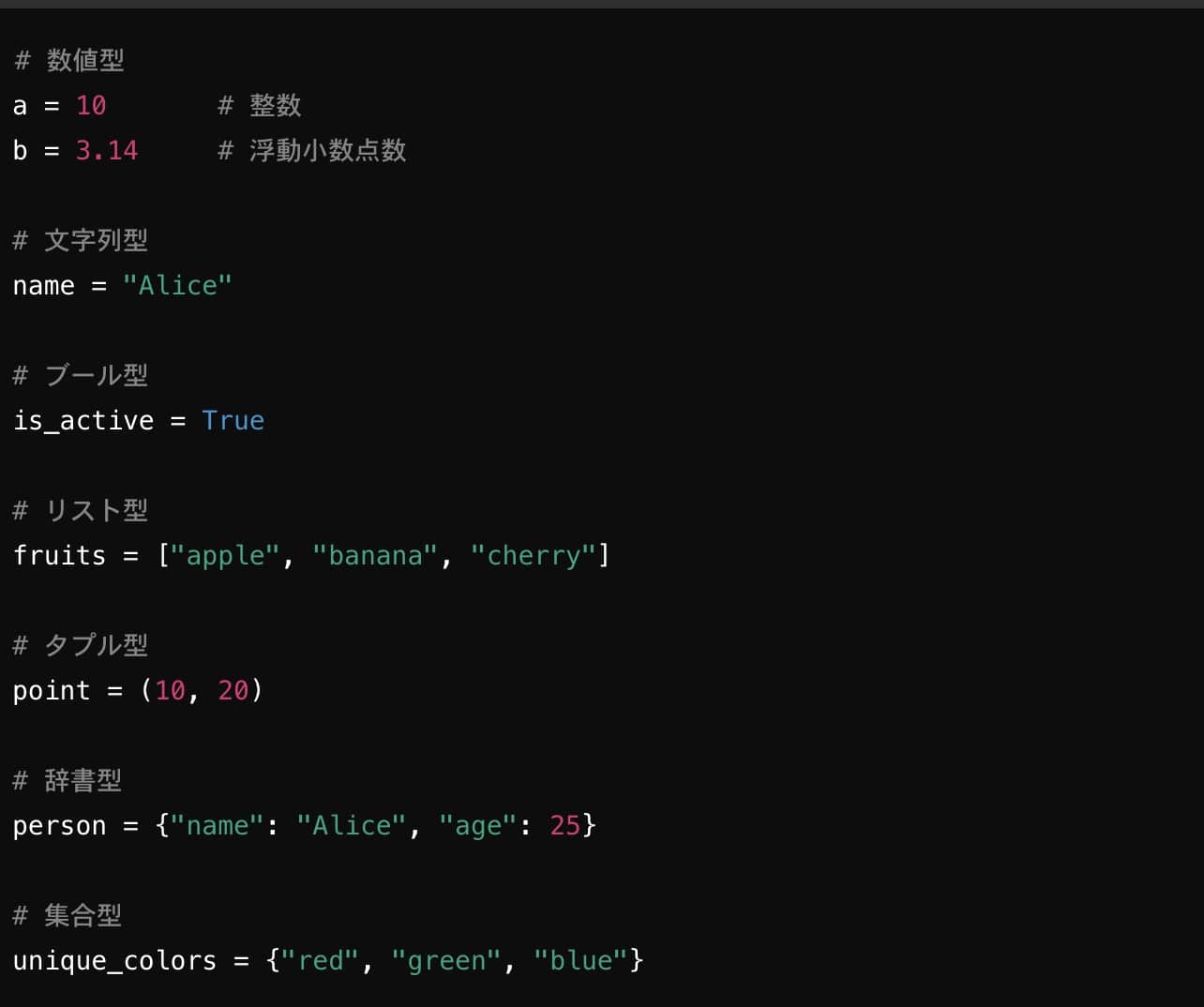
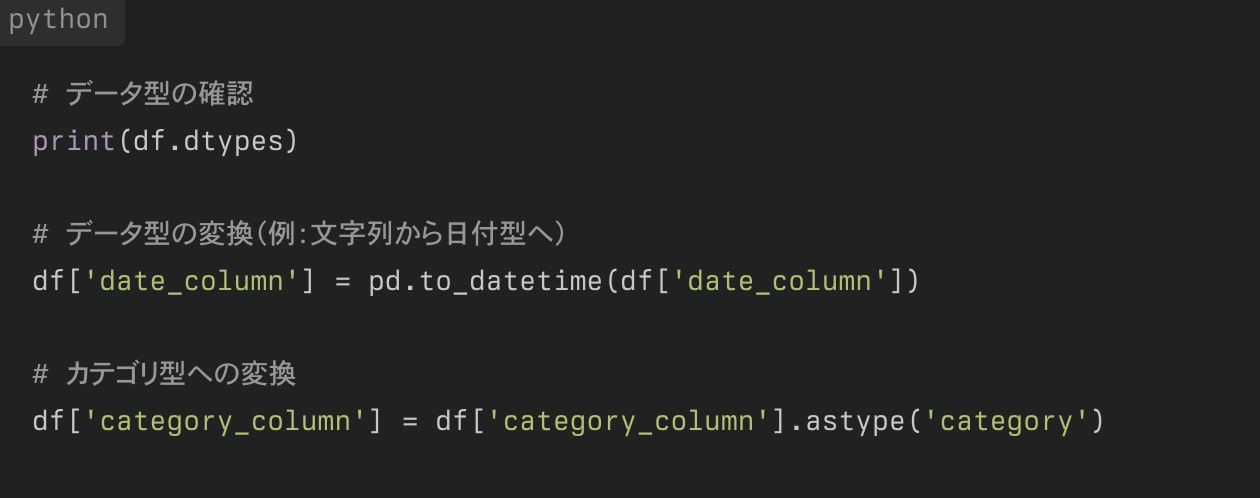
データ型の変換
適切なデータ型を使用することで、メモリ使用量の最適化や操作の効率化が可能です。
ワンポイント解説💡:データ型とは、プログラミングにおいて扱うデータがどのような形式かを定義するものです。データ型を理解することは、プログラムの動作や計算処理において重要です。Pythonなどのプログラミング言語では、変数に格納されるデータの種類に応じて、異なるデータ型が存在します。正しいデータ型を使うことで、エラーを防ぎ、効率的なプログラムを作成できます。
データ型についての詳細解説💡(読みたい人は、右側の矢印をクリックして開いてください。)
- 整数型(int): 小数点を含まない数値を扱います。たとえば、1、100、-50などです。
- 例:
a = 5(aは整数型)
- 例:
- 浮動小数点型(float): 小数点を含む数値を扱います。たとえば、3.14、0.001、-2.5などです。
- 例:
b = 3.14(bは浮動小数点型)
- 例:
- 複素数型(complex): 複素数を扱います。実部と虚部の組み合わせで表され、たとえば
1 + 2jのように、jは虚数単位を表します。- 例:
c = 1 + 2j(cは複素数型)
- 例:
- 文字列型はテキストデータを扱います。Pythonでは、文字列はシングルクォート (
'...') またはダブルクォート ("...") で囲んで表します。- 例:
name = "Alice"(nameは文字列型)
- 例:
- 文字列は不変(immutable)であり、作成後に変更できません。文字列操作には、連結、スライス、検索などが可能です。
- ブール型は、
True(真)かFalse(偽)の2つの値しか持たないデータ型です。論理演算や条件式でよく使用されます。- 例:
is_valid = True(is_validはブール型)
- 例:
- リスト型は、複数の要素を順番に格納できるデータ型で、リストの要素は変更可能(mutable)です。リストは角括弧
[]で囲まれ、要素はカンマで区切ります。- 例:
fruits = ["apple", "banana", "cherry"](fruitsはリスト型)
- 例:
- リストの要素には異なるデータ型も含められ、要素の追加・削除も可能です。
- タプルはリストと似ていますが、変更不可能(immutable)です。一度作成すると、その内容を変更できません。タプルは丸括弧
()で囲みます。- 例:
coordinates = (10, 20)(coordinatesはタプル型)
- 例:
- 不変なデータ構造が必要な場合に使われます。
- 辞書型は、キーと値のペアを格納するデータ型で、キーを使って対応する値にアクセスできます。辞書は波括弧
{}で表し、キーと値をコロン:で区切ります。- 例:
person = {"name": "Alice", "age": 25}(personは辞書型)
- 例:
- 辞書は順序を保持し、要素の追加や削除が可能です。
- 集合型は、重複しない要素を格納するデータ型で、数学の集合のように使います。順序は保持されず、要素の追加・削除が可能です。集合は波括弧
{}で表します。- 例:
colors = {"red", "green", "blue"}(colorsは集合型)
- 例:
- 重複した値が自動的に取り除かれるため、データの一意性が重要な場合に使われます。
データの使用例
以下にPythonのコードで、いくつかのデータ型の使用例を示します。
高度なデータ操作
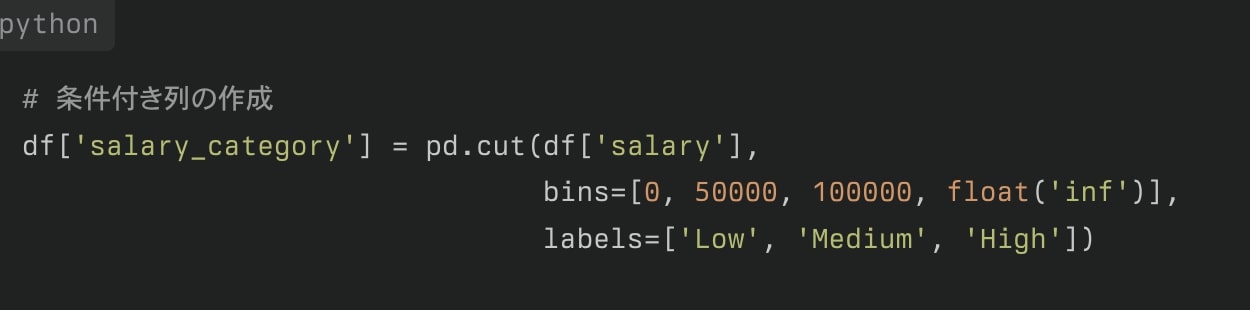
条件付き列の作成
条件に基づいて新しい列を作成することができます。
apply関数の使用
複雑な操作を行うために、apply関数を使用できます。
データの結合
複数のデータフレームを結合することで、より豊富な情報を得ることができます。
時系列データの操作
日付や時間に関するデータを扱う場合、特別な操作が必要になることがあります。
データの出力
分析や操作が完了したデータを保存することも重要です。
これらの操作を組み合わせることで、効率的にデータの前処理、分析、そして結果の出力を行うことができます。
Pandasは非常に強力なライブラリであり、ここで紹介した以外にも多くの機能を提供しています。
実際のデータ分析プロジェクトでは、これらの基本的な操作を組み合わせて使用することになります。
機械学習に必要な統計知識
統計学の重要性
統計学は機械学習の基礎となる重要な分野です。データの特性を理解し、適切なモデルを選択・評価するために不可欠な知識を提供します。
主要な統計概念
記述統計
データセットの特徴を要約するための手法です。
- 中心傾向の指標: 平均値、中央値、最頻値
- ばらつきの指標: 分散、標準偏差
- データの分布: ヒストグラム、箱ひげ図
これらの指標を用いてデータの全体像を把握し、異常値や偏りを検出することができます。
推測統計
サンプルデータから母集団の特性を推定する手法です。
- 確率分布: 正規分布、二項分布など
- 仮説検定: p値、信頼区間
- 回帰分析: 線形回帰、ロジスティック回帰
これらの手法を用いて、データの背後にある関係性や傾向を統計的に検証することができます。
各手法についての説明は別記事取り扱う予定なので、ここでは割愛します。
機械学習との関連
統計学を効果的に学ぶためには、以下のアプローチが推奨されます。
- 基礎概念の理解: 確率論や統計学の基本を学ぶ
- プログラミングスキルの習得: PythonやRを用いた統計解析
- 実データでの実践: Kaggleなどのプラットフォームを活用
機械学習において統計学は不可欠な基礎知識です。
データの特性を理解し、適切なモデルを選択・評価するために、記述統計や推測統計の概念を習得することが重要です。
実際のデータ分析を通じて統計的手法を適用することで、より深い理解と実践的なスキルを得ることができます。
データ前処理のステップと方法

欠損値処理と外れ値の検出
欠損値処理と外れ値の検出は機械学習モデルの性能に大きな影響を与える重要な前処理ステップです。
欠損値処理
欠損値は多くのデータセットに存在し、適切に処理しないとモデルの精度に悪影響を及ぼす可能性があります。
欠損値の検出
まず、データセット内の欠損値を特定することから始めます。

欠損値の処理方法
削除
・行の削除: 欠損値を含む行全体を削除

・列の削除: 欠損値が多い列全体を削除

補完
・平均値、中央値、最頻値での補完

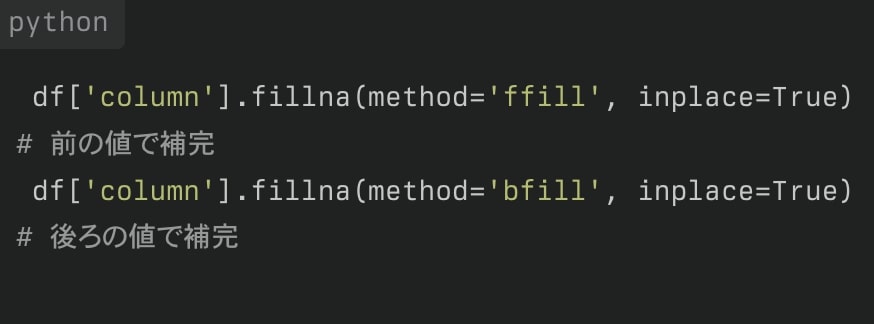
・前後の値での補完(時系列データの場合)
高度な補完方法
- 回帰モデルやKNNを使用した補完
- 多重代入法(Multiple Imputation)
外れ値の検出
外れ値は、データセット内の他の観測値から著しく逸脱した値を指します。これらは分析結果を歪める可能性があります。
外れ値の検出方法
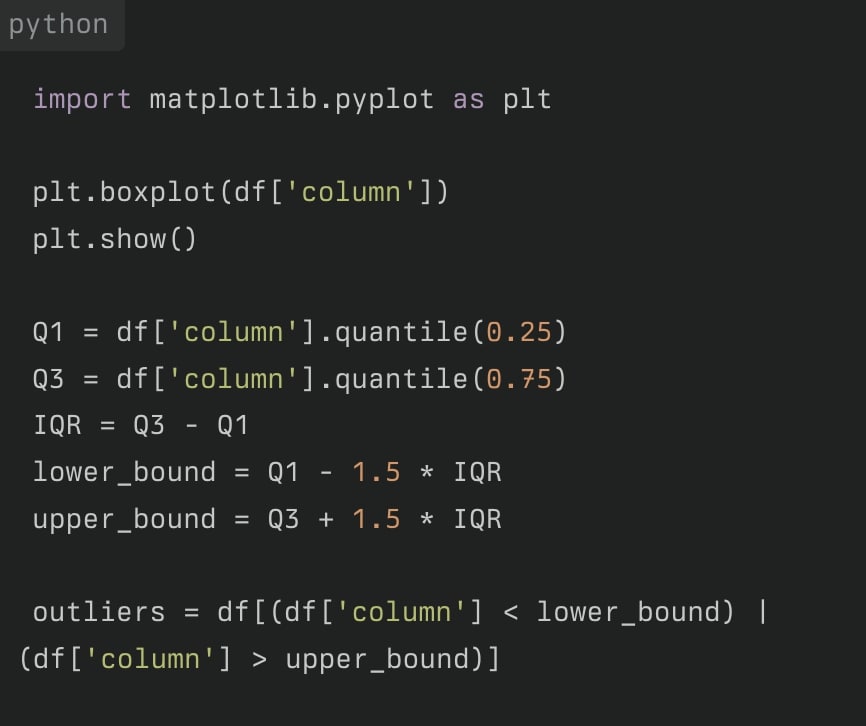
箱ひげ図(Box Plot)による検出
四分位範囲(IQR)を使用して外れ値を特定します。
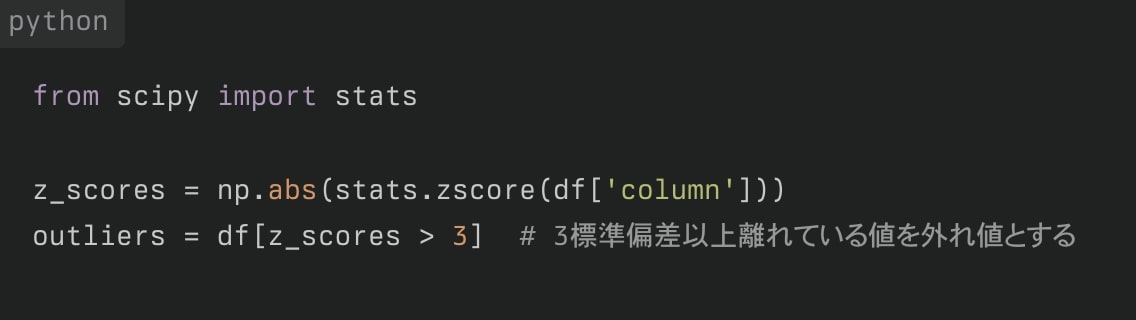
Z-スコアによる検出
データポイントが平均からどれだけ標準偏差離れているかを計算します。
Isolation Forest(アイソレーション・フォレスト)
機械学習アルゴリズムを使用して外れ値を検出します。

外れ値の処理
外れ値を検出した後の処理方法には以下のようなものがあります。
- 削除: 外れ値を含むデータポイントを削除
- 置換: 外れ値を適切な値(例:平均値や中央値)で置換
- 変換: 対数変換などを適用してデータの分布を変える
- 保持: 外れ値が重要な情報を含む場合は、そのまま保持
外れ値の処理方法は、データの性質や分析の目的によって適切に選択する必要があります。
これらの欠損値処理と外れ値検出の手法を適切に組み合わせることで、より信頼性の高いデータセットを準備し、機械学習モデルの性能向上につなげることができます。
データの正規化とスケーリング
ワンポイント解説💡:データの正規化(Normalization)とは、機械学習においてデータを一定のスケールに変換するプロセスのことです。異なる特徴(フィーチャー)の値のスケールが大きく異なる場合、モデルの性能に影響を与える可能性があるため、正規化によってデータのスケールを揃えることが重要です。
例えば、1つの特徴が0〜100の範囲で、もう1つの特徴が0〜1の範囲にある場合、値のスケールが異なるため、特定のアルゴリズム(特に距離ベースのもの、例:KNNやSVM)では、スケールの大きな特徴が過度に影響を与えることがあります。
ワンポイント解説💡:データのスケーリング(Scaling)とは、データの特徴量(フィーチャー)の範囲を調整するプロセスを指します。スケーリングは、特徴量のスケール(値の範囲)が異なる場合に、それらを共通のスケールに合わせて調整することです。スケーリングは、機械学習のアルゴリズムが異なる特徴量の間で一貫性を持って学習できるようにするために重要です。
特徴量が異なるスケールを持つと、例えば、距離ベースのアルゴリズム(K最近傍法、サポートベクターマシンなど)や勾配降下法を使うアルゴリズムにおいて、スケールの大きな特徴量が過度に影響を与えてしまう可能性があります。そのため、スケーリングによって各特徴量の重要性が適切に反映されるようになります。
正規化とスケーリングの重要性
正規化とスケーリングは、機械学習モデルの性能を向上させるために非常に重要な前処理ステップです。これらの手法を適用することで、以下のようなメリットがあります。
- 特徴量間のスケールの違いを解消
- モデルの収束速度の向上
- 特徴量の重要度を均等に扱う
- 一部のアルゴリズムの前提条件を満たす
主な正規化・スケーリング手法
Min-Max正規化(正規化)
Min-Max正規化は、データを0から1の範囲にスケーリングします。

- データが0から1の範囲に収まる
- 元のデータの分布を保持
- 外れ値に敏感
Z-スコア標準化
Z-スコア標準は、データの平均を0、標準偏差を1にします。

- 平均0、標準偏差1のデータに変換
- 外れ値の影響を受けにくい
- 正規分布に従うデータに適している
ロバストスケーリング
中央値と四分位範囲を使用してスケーリングを行います。
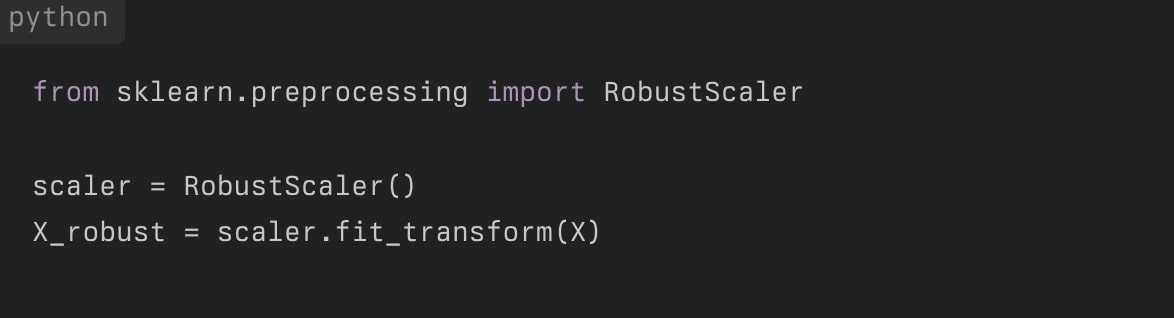
- 外れ値に非常に強い
- 中央値を0、四分位範囲を1にスケーリング
スケーリング適用の注意点
トレーニングデータとテストデータの分割
スケーリングは、データ漏洩を防ぐためにトレーニングデータのみで計算し、その後テストデータに適用します。

特徴量の性質に応じた選択
データの性質や使用するアルゴリズムに応じて、適切なスケーリング手法を選択します。
カテゴリカル変数の扱い
機械学習モデルは、数値データを扱うことを前提にしているため、カテゴリカル変数をそのまま使用することはできません。したがって、以下のような方法で数値データに変換する必要があります。
カテゴリカル変数は、エンコーディング後にスケーリングを適用します。
ワンポイント解説💡:カテゴリカル変数(Categorical variable)とは、機械学習や統計において、値が特定のカテゴリーやグループに分類される変数のことです。数値ではなく、ラベルやクラスのような特定の値の集合から取る変数を指します。カテゴリカル変数は通常、数量的な意味を持たず、以下のような分類やカテゴリーに分けられます。
カテゴリカル変数の例
- 性別:
男性、女性など - 血液型:
A型、B型、O型、AB型 - 国籍:
日本、アメリカ、フランスなど - 商品の種類:
食品、衣料品、電化製品
逆変換の考慮
必要に応じて、スケーリングを元に戻せるようにしておきます。

正規化とスケーリングは、機械学習モデルの性能向上に不可欠な前処理ステップです。
データの性質や使用するアルゴリズムに応じて適切な手法を選択し、適用することが重要です。
また、トレーニングデータとテストデータの扱いに注意を払い、データ漏洩を防ぐことも忘れてはいけません。
これらの技術を適切に使用することで、より精度の高い予測モデルを構築することができます。
カテゴリカル変数のエンコーディング手法とカテゴリカル変数の用途
カテゴリカル変数の種類
- 名義尺度(Nominal scale): 名義尺度のカテゴリカル変数は、カテゴリー間に順序や大きさの関係がないものです。各カテゴリーはただ異なるラベルとして扱われます。
- 例:色 (
赤、青、緑) や都市名 (東京、大阪、福岡)
- 例:色 (
- 順序尺度(Ordinal scale): 順序尺度のカテゴリカル変数は、カテゴリー間に自然な順序やランク付けがあるものです。ただし、カテゴリー間の距離や大きさは明確には示されません。
- 例:教育レベル (
高校卒、大学卒、大学院卒) や顧客評価 (低、中、高)
- 例:教育レベル (
カテゴリカル変数の処理方法(エンコーディング手法)
Label Encoding(ラベルエンコーディング)
各カテゴリに対して一意の整数を割り当てる方法です。
例えば、赤を0、青を1、緑を2とするように、ラベルを数字に変換します。この方法は、カテゴリの順序が意味を持つ場合(順序尺度の変数)に適しています。
One-Hot Encoding(ワンホットエンコーディング)
各カテゴリをバイナリの特徴量(0と1)に変換する方法です。
例えば、赤、青、緑の3つのカテゴリがあった場合、それぞれに対して新しい特徴量を作り、該当するカテゴリには1、それ以外には0を割り当てます。この方法は、カテゴリ間に順序がない場合(名義尺度の変数)に一般的に使われます。
カテゴリカル変数の用途
カテゴリカル変数は、多くの現実世界のデータで頻繁に登場します。
顧客データ(性別、年齢層、地域など)、マーケティング分析(商品の種類、キャンペーンの種類など)、医療データ(病名、症状、治療法など)など、さまざまな分野で使用されます。
カテゴリカル変数を適切に処理し、数値化することで、これらのデータを機械学習モデルで活用できるようになります。
機械学習アルゴリズム基礎編(線形回帰〜SVM)

基本的なアルゴリズムの解説
機械学習アルゴリズムの選択と実装において、まずは基本的なアルゴリズムについて解説します。
ワンポイント解説💡:アルゴリズム(Algorithm)とは、特定の問題を解決するための手順や計算方法を定義した一連のステップのことです。アルゴリズムは、入力を受け取り、その処理を通して望ましい結果(出力)を得るために、明確な順序で実行されるステップを示します。
アルゴリズムの特徴:
決定性: 同じ入力に対して、アルゴリズムは常に同じ出力を提供することが求められます。これは、各ステップが確実に処理を進められるようにするためです。
明確さ(明示性): アルゴリズムは、各ステップが明確であり、曖昧さがなく誰でもその手順に従える必要があります。
有限性: アルゴリズムは、有限のステップで終了しなければなりません。無限に続く処理は、アルゴリズムとして成立しません。
入力と出力: アルゴリズムは1つ以上の入力を受け取り、それに基づいて1つ以上の出力を生成します。出力は、与えられた問題に対する解答となります。
アルゴリズムの重要性:
アルゴリズムは、問題を効率的に解決するために不可欠な要素です。特にコンピュータプログラムの作成において、効率的なアルゴリズムの設計は、処理速度やリソースの消費を抑えるために重要な役割を果たします。効率の悪いアルゴリズムを使うと、時間や計算リソースを無駄にしてしまう可能性が高まります。
基本的な機械学習アルゴリズム
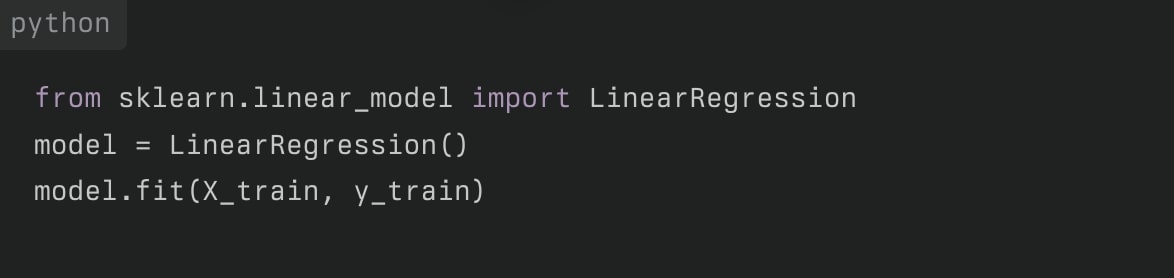
線形回帰
線形回帰(Linear Regression)とは、入力変数と出力変数の間の線形関係をモデル化する最も基本的な手法です。
機械学習や統計学における回帰分析の一手法であり、目的変数(予測したい値)と説明変数(特徴量)との間に直線的な関係があると仮定して、その関係をモデル化する方法です。
特に、線形回帰は数値データを扱い、与えられたデータに基づいて予測や傾向の分析を行います。
- 特徴:
- シンプルで解釈しやすい
- 連続的な数値予測に適している
- 用途:
- 売上予測、価格予測など
ワンポイント解説💡:scikit-learn(sklearn)とは、Pythonで機械学習を行うためのオープンソースライブラリです。scikit-learnは、簡潔かつ効率的に多くの機械学習アルゴリズムを実装するためのツールやモジュールを提供しており、機械学習の基本的なタスク(データの分類、回帰、クラスタリング、次元削減など)に広く使用されています。
豊富な機械学習アルゴリズム: scikit-learnは、多くの一般的な機械学習アルゴリズムを実装しています。例えば、以下のような手法が含まれます:
次元削減:主成分分析(PCA)、因子分析、特異値分解(SVD)など
分類:ロジスティック回帰、サポートベクターマシン(SVM)、決定木、ランダムフォレストなど
回帰:線形回帰、リッジ回帰、ランダムフォレスト回帰など
クラスタリング:K-means、階層クラスタリング、DBSCANなど
ロジスティック回帰
ロジスティック回帰(Logistic Regression)は、分類問題に使用される基本的なアルゴリズムです。
二値分類(バイナリ分類)の問題に広く使われる機械学習アルゴリズムの一つです。
回帰という名前がついていますが、ロジスティック回帰は分類タスクに用いられます。
目的変数(ターゲット)が0または1のように、離散的なカテゴリに分類される場合に、データに基づいてそのクラスに属する確率を予測するモデルです。
- 特徴:
- 二値分類に適している
- 確率を出力できる
- 用途:
- スパム検出、顧客離反予測など

決定木(Decision Tree)
決定木(Decision Tree)は、データの特徴に基づいて分岐を繰り返し、分類や回帰を行うアルゴリズムです。
- 特徴:
- 解釈が容易
- 非線形な関係性も捉えられる
- 用途:
- 顧客セグメンテーション、リスク評価など

ランダムフォレスト
ランダムフォレスト(Random Forest)は、アンサンブル学習の一種で、複数の決定木を組み合わせて予測を行う機械学習アルゴリズムです。
- 特徴:
- 高い予測精度
- 過学習に強い
- 用途:
- 画像分類、金融予測など

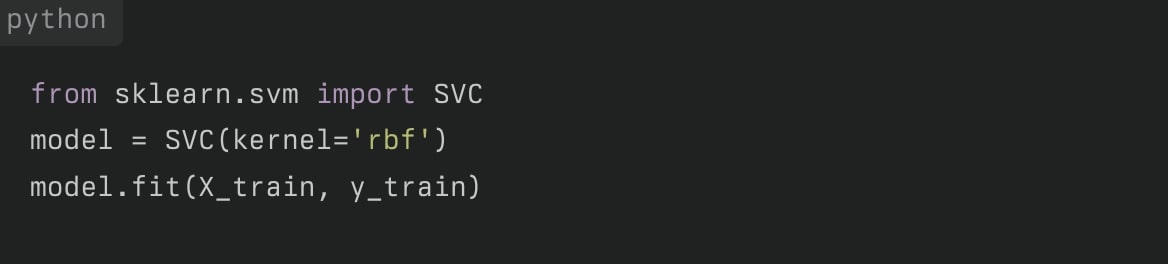
サポートベクターマシン(SVM)
サポートベクターマシン(Support Vector Machine, SVM)は、データ点を高次元空間に写像し、最適な分離超平面を見つけるアルゴリズムです。
- 特徴:
- 高次元データに強い
- カーネルトリックにより非線形分離が可能
- 用途:
- テキスト分類、画像認識など
ワンポイント解説💡:カーネルトリック(Kernel Trick)とは、データを高次元空間にマッピングすることで、非線形なデータでも線形な方法で分類や回帰ができるようにする手法です。
カーネルトリックは、特にサポートベクターマシン(SVM)やその他のアルゴリズムで広く使われ、非線形問題に対処するための強力なツールです。多くの機械学習アルゴリズム(SVMなど)は、データが線形に分離可能な場合にうまく機能します。
しかし、現実のデータはしばしば非線形で、単純な直線や平面でクラスを分けることができない場合が多くあります。そこで、カーネルトリックを使用することで、元の次元(入力空間)では分離できないデータを、より高次元の空間(特徴空間)にマッピングし、そこで線形に分離できるようにするアプローチが取られます。
例えば、2次元のデータが円状に分布している場合、2次元の平面では直線で分けることができませんが、3次元やさらに高次元の空間にデータをマッピングすることで、線形分離が可能になる場合があります。
これらの基本的なアルゴリズムは、多くの機械学習タスクの基礎となります。
問題の性質や利用可能なデータに応じて、適切なアルゴリズムを選択することが重要です。
また、これらのアルゴリズムを組み合わせたり、より高度なアルゴリズム(ニューラルネットワークなど)を使用したりすることで、さらに複雑な問題に対応することができます。
モデル評価のための指標と方法
機械学習における評価指標は、モデルの性能を定量的に評価するための基準です。
評価指標を使用することで、モデルがどれだけ正確に予測を行ったか、どのような誤りをしているかを把握し、改善すべきポイントを見つけることができます。
モデルのタスク(分類、回帰など)によって適用される評価指標は異なります。
分類問題の評価指標
分類問題では、目的変数がカテゴリデータ(例:スパム/非スパム)となるため、モデルが正確にクラスを分類できるかを評価します。
混同行列(Confusion Matrix)
混同行列は、実際のクラスと予測されたクラスの組み合わせを行列形式で表示します。各項目は以下のように定義されます。
- True Positive (TP):実際にポジティブなクラスがポジティブと予測された数。
- True Negative (TN):実際にネガティブなクラスがネガティブと予測された数。
- False Positive (FP):実際にはネガティブなクラスがポジティブと予測された数(誤検出)。
- False Negative (FN):実際にはポジティブなクラスがネガティブと予測された数(見逃し)。
混同行列を基に、多くの評価指標を計算できます。
正解率(Accuracy)
正解率は、全体のデータに対して、正しく予測されたデータの割合です。
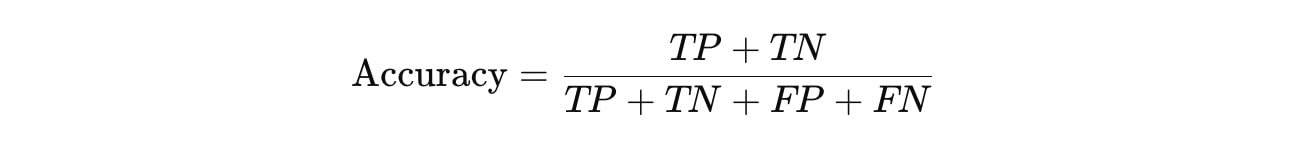
ただし、クラスの不均衡(例:ポジティブクラスが少ない場合)では不適切な指標となることがあるため注意が必要です。
適合率(Precision)
適合率は、ポジティブと予測したデータのうち、実際に正しかった割合です。誤検出(False Positive)をどれだけ減らすかに関心がある場合に重要な指標です。
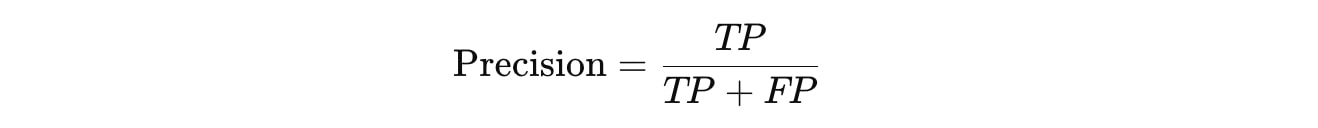
再現率(Recall)
再現率は、実際にポジティブだったデータのうち、正しくポジティブと予測された割合です。見逃し(False Negative)を防ぐことが重要な場合に有効です。
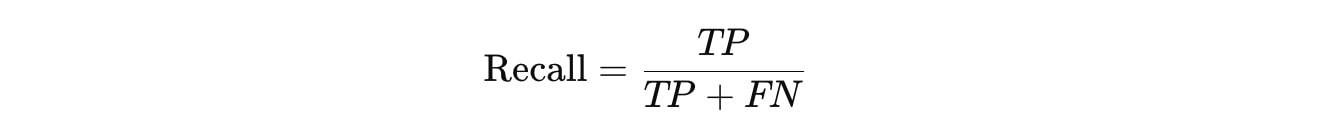
F1スコア(F1 Score)
F1スコアは、適合率と再現率の調和平均を取ったもので、両者のバランスが重要な場合に使用されます。適合率と再現率のバランスが取れているか確認する指標です。
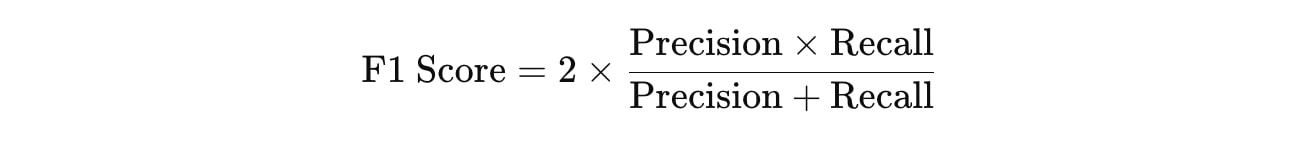
ROC曲線とAUCスコア
- ROC曲線(Receiver Operating Characteristic Curve)は、再現率(True Positive Rate)に対する偽陽性率(False Positive Rate)のグラフです。
- AUC(Area Under the Curve)は、ROC曲線の下の面積で、モデルの分類性能を評価します。1に近いほど良いモデルです。
これらは、分類の性能を総合的に評価するのに適しています。
回帰モデルの評価指標
回帰モデルでは、目的変数が連続値(例:家の価格など)であるため、予測された値と実際の値の誤差に基づいて評価を行います。
平均二乗誤差(MSE: Mean Squared Error)
MSEは、実際の値と予測された値との差を二乗し、その平均を取ったものです。誤差が大きくなると、値が大きくなるため、大きな誤差に対してペナルティがかかります。
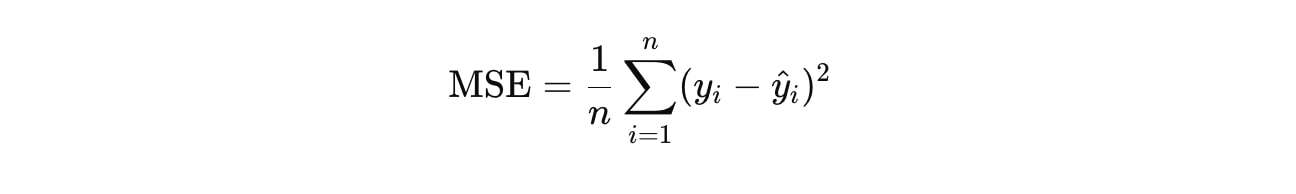
yi は実際の値、y^i は予測された値。
平均絶対誤差(MAE: Mean Absolute Error)
MAEは、実際の値と予測された値の絶対差を平均したものです。大きな誤差と小さな誤差を同等に評価します。
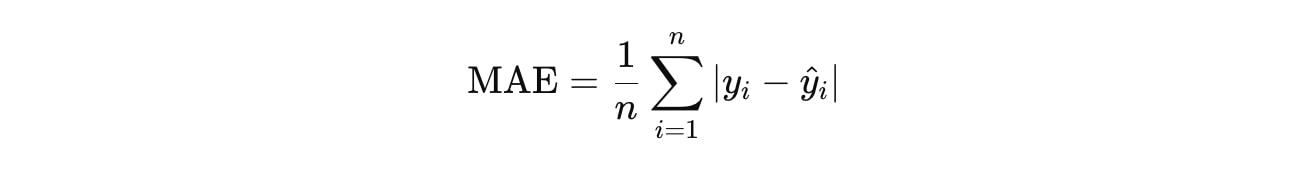
決定係数(R²スコア)
R²スコアは、モデルがデータの分散をどれだけ説明できているかを示す指標で、0から1の範囲で評価されます。1に近いほど、モデルがよくデータを説明できていることを意味します。
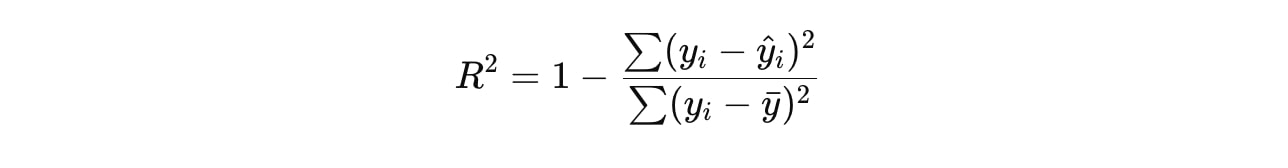
yˉ は実際の値の平均です。
評価方法
クロスバリデーション
クロスバリデーションは、モデルの汎化性能を評価するための手法です。
データを複数の分割に分け、各分割でモデルを訓練し、他の分割で評価を行います。
最も一般的な手法はk分割交差検証(k-fold cross-validation)で、データセットをk個に分け、k回の訓練と評価を行い、全体の評価結果を平均します。
ホールドアウト法
ホールドアウト法は、データセットをトレーニングセットとテストセットに分割し、トレーニングセットでモデルを学習させ、テストセットで評価を行います。
ブートストラップ
ブーストラップは、データセットからランダムにサンプリングを行い、複数のサブセットを作成して評価を行います。
これらの指標と方法を適切に組み合わせることで、モデルの性能を多角的に評価し、改善につなげることができます。問題の性質や目的に応じて、適切な評価指標と方法を選択することが重要です。
クラス不均衡における評価指標
データセットにクラス不均衡がある場合(例:病気の診断で、患者の割合が非常に少ない場合)、正解率(Accuracy)だけではモデルの性能を十分に評価できません。例えば、99%の健康な人と1%の病気の人のデータでは、常に「健康」と予測するだけで99%の正解率が得られます。
この場合、適合率、再現率、F1スコアなど、より細かい評価指標を使用することで、モデルの実際のパフォーマンスをより正確に評価できます。
機械学習における評価指標
機械学習における評価指標は、モデルの種類やデータセットの特性に応じて使い分ける必要があります。
主な分類問題の評価指標には、正解率、適合率、再現率、F1スコア、ROC-AUCなどがあり、回帰モデルではMSE、MAE、R²スコアがよく使われます。クロスバリデーションを使用することで、モデルの汎化性能を高め、安定した評価を行うことができます。
Pythonでのアルゴリズム実装例
Pythonでの機械学習アルゴリズムの実装例について、解説します。
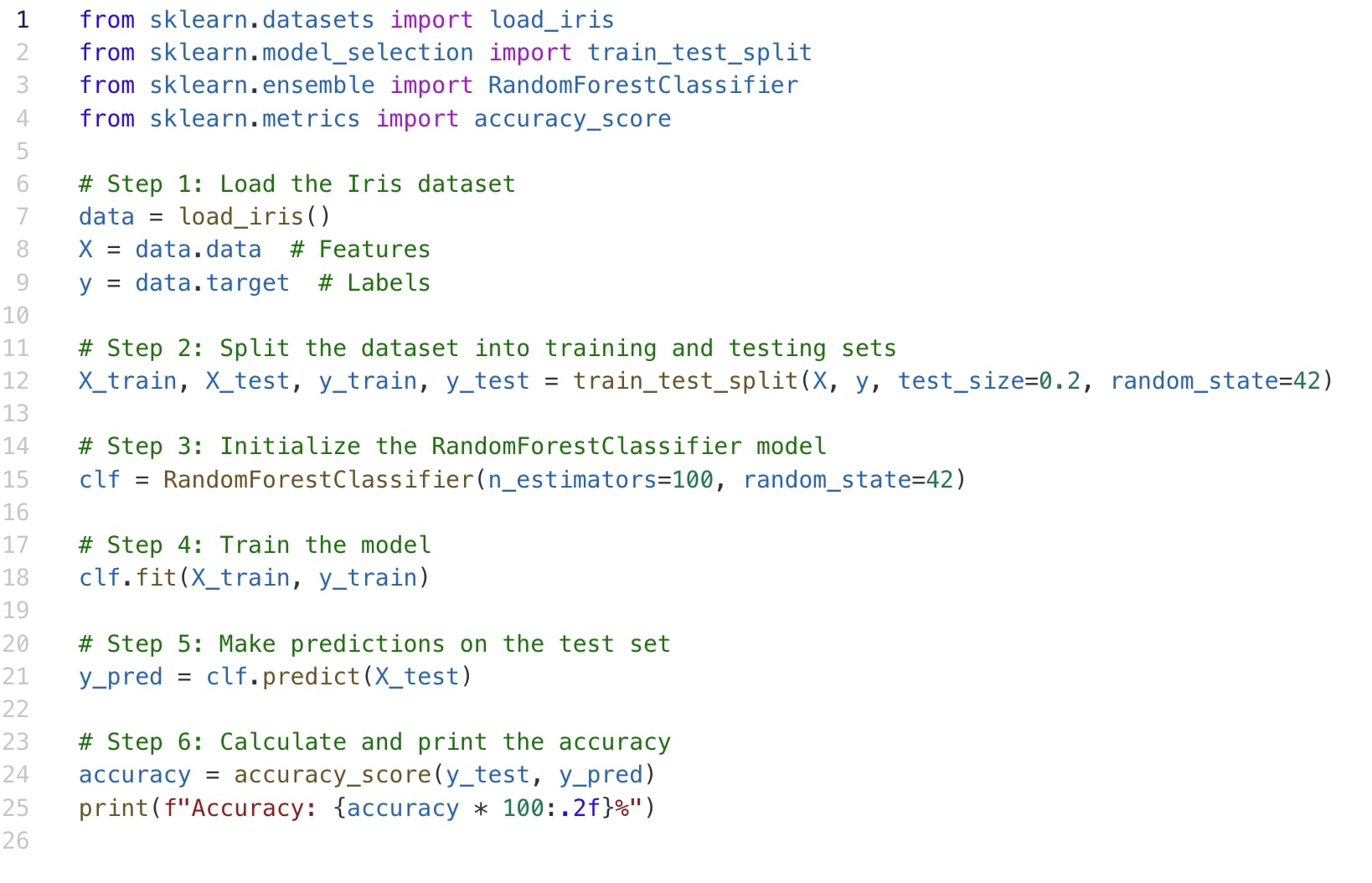
このコードはランダムフォレスト分類器を使用してアイリスデータセットを分類する例を示しています。
コードの解説
ライブラリのインポート

必要なライブラリをインポートしています。
scikit-learnは機械学習のための豊富なツールを提供してくれます。
データの準備

アイリスデータセットを読み込み、特徴量とラベルに分けています。
データの分割

データセットを訓練用とテスト用に分割しています。test_size=0.2はテストデータの割合を20%に設定しています。
モデルの作成と学習

ランダムフォレスト分類器を作成し、訓練データで学習させています。n_estimators=100は決定木の数を100に設定しています。
ワンポイント解説💡:ランダムフォレストモデルのパラメータ設定について
ランダムフォレストモデルのパラメータ設定の方法
1. グリッドサーチ(Grid Search)
・パラメータの組み合わせを網羅的に試す方法
・scikit-learnのGridSearchCVを使用
2.ランダムサーチ(Random Search)
・パラメータの組み合わせをランダムに試す方法
・Grid Search CVよりも効率的に広い範囲を探索可能
・Randomized Search CVを使用
3. ベイズ最適化
・過去の探索結果を考慮して効率的にパラメータを探索
・scikit-optimizeなどのライブラリを使用
4. 手動チューニング
・経験則や問題の性質に基づいて手動で調整
・例:n_estimatorsは多いほど精度が上がるが、計算コストとのトレードオフを考慮
主要なパラメータ
・n_estimators: 決定木の数(多いほど精度が上がるが、計算コストも増加)
・max_depth: 木の最大深さ(深いほど複雑なパターンを学習できるが、過学習のリスクも増加)
・max_features: 分割時に考慮する特徴量の数(’sqrt’や’log2’がよく使われる)
・min_samples_split: 内部ノードを分割するのに必要なサンプル数の最小値
・min_samples_leaf: 葉ノードに必要なサンプル数の最小値
予測と評価

テストデータで予測を行い、その精度を計算しています。
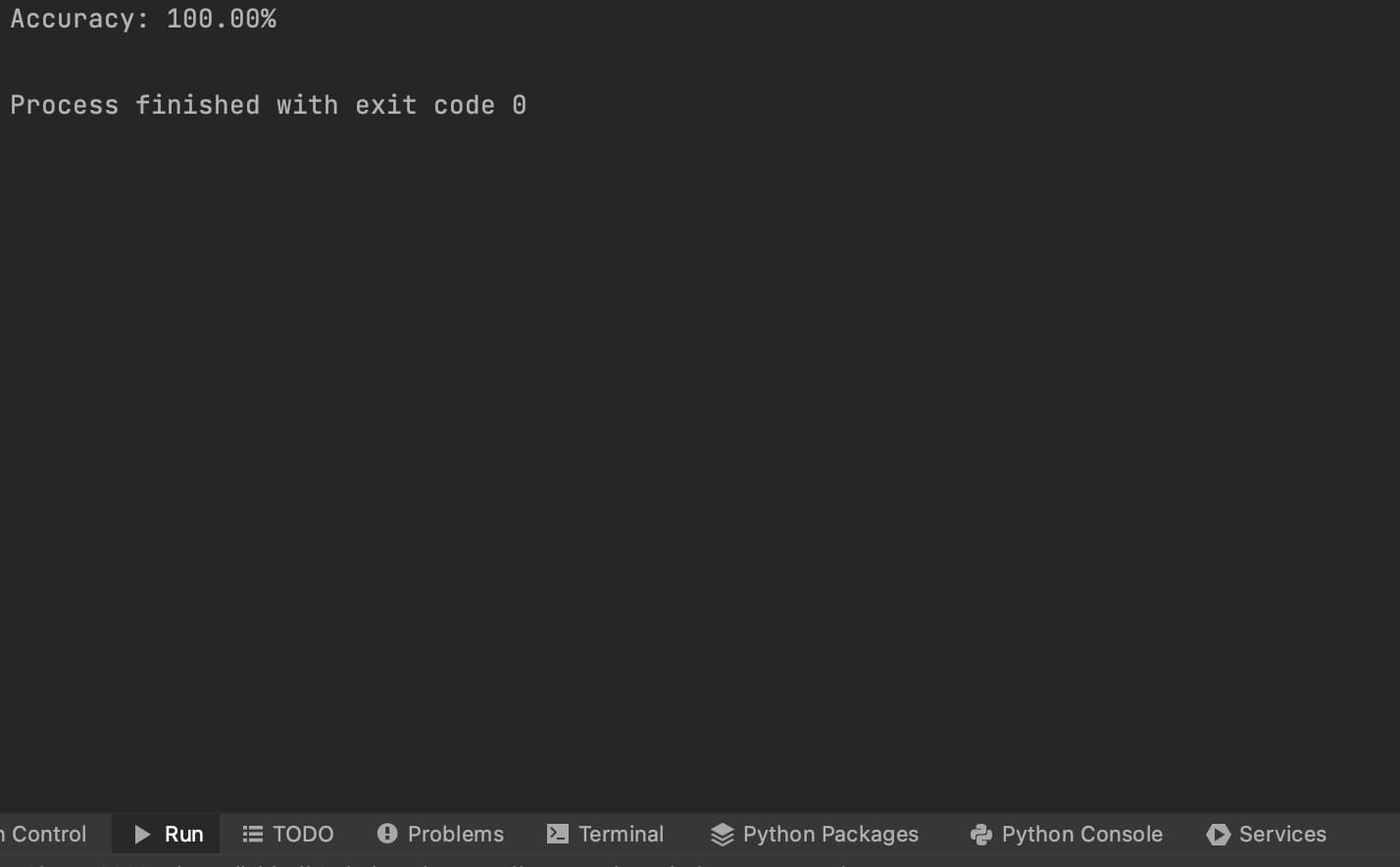
結果の解釈
実行結果が100.00%となっていることから、このモデルはテストデータに対して100%の精度を達成したことがわかります。しかし、これは小規模なデータセットであるアイリスデータを使用しているためで、実際の問題ではこのような完璧な精度を得ることは稀です。
- データの前処理: この例では簡単のため省略されていますが、実際のプロジェクトではデータのクリーニングや正規化が重要です。
- モデルの選択: 問題の性質に応じて適切なアルゴリズムを選択します。ここではランダムフォレストを使用しています。
- ハイパーパラメータの調整: モデルの性能を最適化するために、ハイパーパラメータ(この例ではn_estimators)を調整します。
- 評価指標の選択: 問題に応じて適切な評価指標を選びます。ここでは精度(accuracy)を使用しています。
- クロスバリデーション: より信頼性の高い評価のために、クロスバリデーションを実施することが推奨されます。
このような基本的な実装を理解し、実際の問題に応用していくことが機械学習アルゴリズムの実装において重要です。
まとめ
この記事では、機械学習に関する基礎知識の復習から、メインとしてデータの準備、前処理の重要性から実際の処理の流れ、そして機械学習のアルゴリズムの第一章として線形回帰〜サポートベクターマシン(SVM)を解説し、モデルの評価指標の選択、実際の実装例を解説しました。
最後にもう一度簡単におさらいしましょう。
機械学習モデルの成功の鍵を握る重要なステップは「データ準備」と「前処理」です。いかに高度なアルゴリズムを使用しても、質の低いデータでは満足な結果を得ることはできません。データ準備と前処理には、データの収集からクレンジング、特徴量エンジニアリングまでが含まれます。これらの工程は、モデルの精度向上に直結する重要なステップです。
- データ準備の重要性
-
機械学習モデルの精度や信頼性は、使用するデータの量と質に大きく依存します。収集するデータは、解決したい問題を代表するものであることが重要で、様々なシナリオや条件を網羅したデータを集めることで、モデルの汎用性が向上します。
- 前処理の重要性
-
収集したデータは、欠損値、外れ値、ノイズなどの問題を抱えることが多く、これらを適切に処理しないとモデルの精度に影響を与えます。また、データを正規化したり、特徴量エンジニアリングを行うことで、モデルの性能を劇的に向上させることができます。例えば、データのスケーリングなどの技術が効果的です。
これらのステップを丁寧に行うことで、過学習のリスクを減らし、学習時間を短縮し、モデルの解釈性を向上させることができます。初めて機械学習を学ぶ場合、これらの基本的なデータ準備と前処理の技術をしっかりと理解することが、成功への第一歩となります。
機械学習におけるアルゴリズムは、データを元にパターンや規則性を見出すために使用されます。
| アルゴリズム | 種類 | 対象データ | 主な用途 | 特徴 |
|---|---|---|---|---|
| 線形回帰 | 教師あり | 数値 | 連続値の予測 | 入力変数と出力変数の線形関係をモデル化。売上予測、価格予測など |
| ロジスティック回帰 | 教師あり | カテゴリ | 二値分類 | データを0か1のように分類。スパム検出、顧客離反予測など |
| 決定木 | 教師あり | 数値・カテゴリ | 分類・回帰 | 特徴に基づいて木構造の分岐を繰り返す。顧客セグメンテーション、リスク評価など |
| ランダムフォレスト | 教師あり | 数値・カテゴリ | 分類・回帰 | 複数の決定木を組み合わせたアンサンブル学習。画像分類、金融予測など |
| サポートベクターマシン(SVM) | 教師あり | 数値・カテゴリ | 分類・回帰 | データを高次元空間に写像し、最適な分離超平面を見つける。テキスト分類、画像認識など |
これらのアルゴリズムは、問題に応じて適切に選択し、さらにハイパーパラメータの調整などを行うことで、モデルの精度を向上させることが可能です。
次の記事では、機械学習のアルゴリズムについてさらに多くの種類を含め、より深いポイントにフォーカスした機械学習アルゴリム第二章となります。
 massa
massa当ブログでは、初心者からでもAIを学べるようAIについての知識の集約、解説、ChatGPTのおすすめスキルなどを発信して行きます。
よかったら、是非、ブックマーク&フォローしてください。
-

機械学習について学ぼうシリーズ②初心者向け!機械学習で必須のデータ準備と前処理テクニック〜機械学習アルゴリズム第1章
-
OpenAIが導入した「ChatGPT Canvas」最新機能を紹介! 基本的な使い方から活用方法まで詳細に解説
-
機械学習について学ぼうシリーズ①機械学習とAIとの違いって?ディープラーニングは何が違う?
-
ChatGPT 高度な音声モードついに一般向けリリース!ChatGPTで実現するリアルタイム会話の可能性 次の時代は音声モードへ!?
-
ChatGPTの最新情報!最新モデルOpenAI-o1とは?使い方やGPT-4oとの比較、その活用方法、応用分野や今後の展望について
-
Open AI 次世代モデル『GPT NEXT』、プロジェクトStrawberryとは?|AIの驚異的な進化スピードによる今後の展望






